AMDのA10-5800Kのベンチを取ってみた
AMDの勉強会でお土産としてA10-5800Kとマザーボードをいただきました。それでPCを組み立ててベントとかベンチとかベンチとか取ってみました。
構成は以下になります。
CPU:A10-5800K
GPU:AMD Radeon HD 7660D
ストレージ:Intel 520 180GB
メモリ:DDR3-1333 8GB x2
OS:Windows 8 64bit RTM
メモリがしょぼいですが、手元にあるのがこれでした。
比較するのが私が今メインに使用している以下の構成です。
CPU:Phenom II X6 1090T
GPU:Radeon HD 6750
SSD:Intel 510 120GB x2(RAID 0)
メモリ:DDR2-800 2GB x4
OS:Windows 7 64bit
比較するのに条件をあわしていないとかあれなのですが、これは私のPCの世代交代を行うためなので。
まずはA10-5800Kが構成は以下になります。
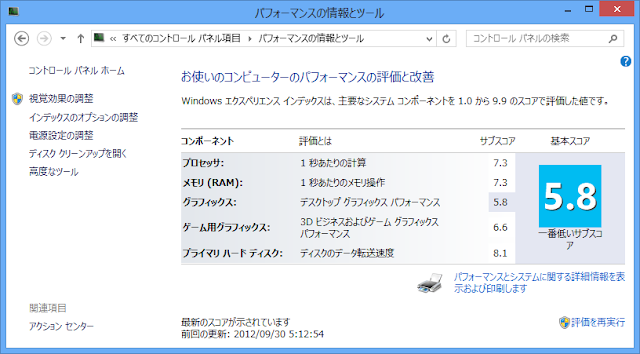
■Windowsエクスペリエンスインデックス
■デバイスマネージャー

■CPU-Z

■GPU-Z

ベンチは以下を行いました。
■Sandra

■3DMark 11(P)

■Heaven DX11 Benchmark 3.0

■CINEBENCH R11.5

■ブラウザベンチ
・Octane
・Peacekeeper
・webworkerベンチ(ここにあるwebworkerssample.zip)
■OpenCL N-Body

結果は以下になります。
| Bench | A10-5800K | Phenom II X6 1090T& Radeon HD 7750 |
| Sandra CPU Dhrystone(GIPS) | 51.61 | 67.54 |
| Sandra CPU Whestone(GFLOPS) | 35.54 | 56.34 |
| Sandra GPU CPU+GPU(Mピクセル/s) | 657.01 | 1045.99 |
| Sandra GPU GPU(Mピクセル/s) | 643.04 | 1034.02 |
| Sandra GPU CPU(Mピクセル/s) | 62.83 | 65.11 |
| 3DMark11(P) | P1369 | P2310 |
| Heaven DX11 Benchmark 3.0(FPS) | 22.5 | 34.1 |
| CINEBENCH R11.5 OpenGL(fps) | 30.11 | 53.48 |
| CINEBENCH R11.5 CPU(pts) 1コア | 1.08 | 1.01 |
| CINEBENCH R11.5 CPU(pts) 全コア | 3.20 | 5.53 |
| Octane(Chrome 22) | 13,534 | 11,757 |
| Peacekeeper(Chrome 22) | 3,772 | 3,779 |
| webworkerベンチ(Chrome 22) 1スレッド(ms) | 978 | 1,050 |
| webworkerベンチ(Chrome 22) 最速(ms) | 255 | 200 |
| OpenCL N-Body(GFLOPS) CPU | 38.70 | 58.85 |
| OpenCL N-Body(GFLOPS) GPU | 210.96 | 393.19 |
外付けGPUマシンと比較するのはA10-5800Kには不利ですが、A10-5800Kでベンチを取ってみて3つのことに気付きました。
1つ目は案外シングルスレッドの性能が高いことです。
Phone II X6はIstanbulはほぼ最後のSTARSコア(Llanoが最後のコアですが性能的アップはないはず)です。A10-5800KのCPUコアは、Bulldozer系のPiledriverです。Bulldozer系はIPCを上げずにコア数と高い周波数で性能を上げるCPUコアです。このため、シングルスレッドはそれほど高くないと考えていましたが、ブラウザベンチやCINEBENCH R11.5でシングルスレッドを選択するとIstanbulよりも高速でした。
CPUは多コアの時代に突入していますが、アプリによってはシングルスレッドで動くものが多くあります。その典型的なものがブラウザ(と言うか、JavascriptでWebWorkerに対応していない)です。と考えるとPiledriverで案外性能アップを体感しやすいのかも知れません。
2つ目は内蔵GPUの性能が高いことです。
SandraとOpenCL N-Bodyベンチで、CPUとGPUと混在のベンチが取れます。両方ともGPUの方が性能が桁違いに高いです。CPUがヘテロジニアスマルチコアに進む理由がここに表れています。
ベンチだけ速くても意味がありません。WinZip等はOpenCLを活用して高速化を果たしているアプリも少しは出てきています。鶏が先か卵が先かの問題になりますが、アプリが増えればヘテロジニアスマルチコアの有効性が出てきます。
3つ目は、2つ目と関係するのですがBulldozer系の浮動小数点演算の性能がやっぱり悪いとなと。
Bulldozer系は1モジュールで2コア搭載し、浮動小数点演算は2コアで共有する形になっています。このため、浮動小数点演算の性能が悪いのではないかと思っていました。Sandraの結果を見ていると浮動小数点演算のっけは、整数演算の性能比よりも悪い数字が出ています。
ここにAMDのビジョンが見えてきます。OpenCLのベンチを見ても浮動小数点演算の性能に関しては、CPUはGPUに勝てません。ならば浮動小数点演算をCPUでやらずにGPUにさせるほうが性能をアップできます。そうなればCPUの浮動小数点演算の性能をアップするよりも、HSAやGPUとの連携できる仕組みを作って大幅に性能を上げたほうがメリットが大きいと考えるのは至極妥当です。スパコンでは既にGPUを使ったシステムが多用されていることがこの証明になります。
現時点ではAMDはサーバにもAPUを展開するとアナウンスしています。このた、GPUを搭載したAPUでない製品は最終的にはなくなるでしょうし、HSAが普及すればCPUに浮動小数点演算を搭載することはオワコンになっているかも知れません(いつになるか分かりませんが)。
将来的のロードマップは分かりませんが、A10-5800Kのベンチを見ているとそんな気がさせれれます。
実を言えば、私はAPUに移行をしたいと考えていましたが、前製品であるLlanoで移行しなかった理由は、ソケット寿命が短いことが分かっていたためです。Trinityで採用しているFM2は、次の製品までサポートすることを明言されています。自作ユーザではアップグレードパスの有無は小さくないと思います。
このため、私はLlanoを回避してTrinityで移行予定でしたが、現在使用しているPhonem IIX4 & Radeon HD 6750から移行することにどの程度メリットがあるかが心配でした。今回CPUとマザーボードをいただいたことでその踏ん切りをつけることが出来ました。AMD様、勉強会、CPU、マザーボードありがとうございました。大切に使用させていただきます。