SpamAssassinのこと(3)
テスト内容は、日本語で書いたルールが正しく使われるか、およびベイズフィルタの精度が変わるか(向上するか)です。
まず、UTF-8コードが使えるエディタでルールファイルを作成し、メールヘッダや本文中の単語にマッチするかを調べました。わかち書きを行った結果のメールと照合することになるため、ルールもわかち書きした結果と同じように書かなければなりません。この点が少々面倒ですが、わかち書きした結果と同じテキストをルールに記述しておけば、正しく処理されることが確認できました。
ただ、この点については、文字セットを内部的に統一しただけのメール、つまりわかち書きしないメールと照合する方式にする方がいい、という意見もあります。ルールに書くテキストをわかち書きしなくてもいいからです。SpamAssassinの開発用メーリングリストでも話題になりました。日本語を常用しない人に説明するのが難しく、まだ完全に同意してもらえたわけではないのですが、私は次の2つの理由により、わかち書きした結果のメールテキストと照合する方がいいと思っています。
- 単語の途中で改行された場合でも、Kakasiなどのわかち書きプログラムは単語をつないでくれる。
- 辞書の語彙に左右されるが、たとえば「人情」という言葉をマッチさせたいと思ったときに、「個人情報」もマッチしてしまう(「個人」と「情報」にわかち書きされていたらマッチしない)
次にベイズフィルタですが、昨年私が受け取ったビジネス上の正規メールで、以前のバージョンではスパムと判断されていたもの100通程度、最近の日本語スパム100通程度を実際に処理してみました。比較のために、日本語対応パッチを適用していない旧ロジックと、適用した新ロジックの両方で処理しました。
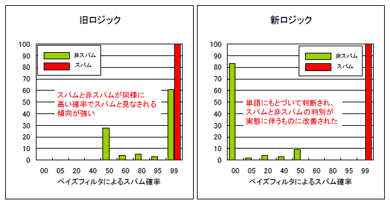
ベイズフィルタの判断結果は BAYES_50、BAYES_99などの「スパムである確率」になります。数字が大きいほどスパムである疑いが強いので、正規メールがSPAM_99などの判定結果になるのはまれであってほしいということになります。
結果のグラフ (拙著「日本語スパムへ一石を投じる『日本SpamAssassinユーザ会』設立 」から)を見ていただくとわかりますが、旧ロジックでは非スパム(正規メール)はすべて50%以上の確率になっているのに対して、新ロジックではすべてが0%から50%になりました。一方スパムはどちらでも99%になりました。つまり、旧ロジックではスパムと正規メールをあまり区別できないのに対して、新ロジックでは高い精度で区別できるようだ、ということが明確になりました。
{kind=link}
SpamAssassinは、キーワードマッチ、ベイズフィルタ以外にもいくつかの判断方法を備えています。日本語パッチを適用したSpamAssassinにその他の判断方法も追加して、約5ヶ月使ってきましたが、今のところスパム判定精度は99パーセント以上というきわめて良好な結果が得られています。
次回は、このパッチに対して指摘された改善すべき点などについてまとめる予定です。
つづく