文系のためのデータサイエンス
最近、「データサイエンス」が注目を浴びています。
文系の方は、「何だか、難しそう」、「理系の一部の人のもの」と敬遠してしまうケースも多いと思いますが、DX(デジタルトランスフォーメーション)が叫ばれる中、文系・理系、関係なく、必須のビジネス・スキルになってきています。
「工業」大学の「文系」学科で、「経営」系と「情報」系の科目を担当している私としては、学生に「どの範囲をどこまで身につけてもらうか」、「どうやって身につけてもらうか」は重要なテーマで、日々、悪戦苦闘しています。
この時期、新たな年度を迎える前の充電期間ということで、「データサイエンス」、「文系」をキーワードに、関連図書を読み漁っています。
今回は、その中のいくつかについて、ピックアップしてみたいと思います。
といっても、書評とか、オススメの本を紹介する、といった趣旨ではありません。
あくまでも、個人的な読書感想文ですが、この手の本の選び方、デジタルサイエンスを学ぶ上での注意すべき点など、参考になればと思います。
●総合法令出版「文系のための データサイエンスがわかる本」高橋威知郎(2019/09)
著者は、企業のデータ分析やそのコンサルティングなどを行っている会社の代表取締役をされている方です。
タイトルは、求めていたものズバリで、「データサイエンスを学ぶ人が最初に読むべき1冊」「本物のデータ分析力が身に付く」と帯に書いてあり、期待を持って読みましたが、手順や例題などは無いので、これを読んでもデータ分析ができるようには、ならないです。
データサイエンスがわかる学術書ではなく、データサイエンティストにまつわるお話がネタとしてできるようになる教養本という感じです。
内容的には、データサイエンスを教える立場の人間からすると、もやっとする感じのことが多いです。
例えば、「こつこつとヒットを打っていれば、そのうちのいくつかはホームランになります」と書いてあって、イチローの打率とホームラン数の年度別の推移を示した折れ線グラフが参考に載せてあるのですが、データサイエンティストだけでなく、野球好きも、もやっとすると思います。
この折れ線グラフは、「ヒットの数が多ければ、ホームラン数が増える」という因果関係を示そうとしたのだと思いますが、これって、相関(AとBの変化に関係がある)がありそう、ということが見て取れるだけで、因果(Aが原因となってBが変動する)とはいえません。
野球好きとしては、むしろ、「ヒットの延長線上がホームランになることはなく、ホームランを狙ったものがヒットになることはある」と言いたいところです。「フライボール革命」の話を持ち出すまでもなく、ホームランを狙ったときとヒットを狙ったときでは、スイング、ボールの発射角度は違います。
ちなみに、イチローは現役時代、「もし、打率.220でよければ、40本打てるけれども、誰もそれを望んではいないでしょ」と話しています。また、イチローがバッティング練習でポンポンとスタンドに放り込んでいる姿を見て、コーチや解説者が「イチローはホームラン競争に出れば優勝する」と話しています。そうなると、グラフは、イチローがホームランを狙う割合を年度別に示したものに見えてきます。
少なくとも「ヒットの数とホームラン数」の相関を示すのであれば、イチロー「個人」の成績だけを「複数年」で比較するのではなく、その年の試合数とか使用球(飛ぶボールとか)のこともありますので、「多くの選手」の成績を「単年」で比較すべきだと思います。
しかも、折れ線グラフでは、「なんとなく関係がありそう」ということが分かるだけで、これだと、思いつきの域を超えていません。散布図を使って表現し、さらに、相関係数など、合理的で客観的な数字で、根拠を示す必要があります。
イチローの話と折れ線グラフは、「データサイエンスは、小さくコンパクトに始めて、大きな成果を生むテーマを探す」ということを説明するためのたとえ話なので、「たとえ話に突っ込むのって著者に酷かな」という気もしますが、こういうイメージだけで判断させようとするデータの見せ方は、「データサイエンスと相反する」ことだと思うのです。
さらに、もやっとする部分をもう一つ。企業の事例を紹介するところで、「数理計画法」という言葉が出てきます。「データサイエンスの導入にあたっては、社内に数理計画法などをやっている人がいるので、そういう人を利用しましょう」というようなことなのですが、それって、「これからデータサイエンスを学ぼうとする文系の人に言う言葉」ではなく、「データサイエンスを進めたいと思っている技術をあまり知らない経営者に対して話すこと」ですよね。
「数理計画法」についての説明はほとんどありません。
「昔からあるデータサイエンス技術です」「それほど難しいものではなく、すぐに実現可能なものです」「この手の専門家は50代の方が多い印象があります。あと20年もすれば確実に企業からいなくなります」「外部から人を呼ぶのもいいですが、そういった社内人財を探し出し活躍していただくのも手だと思います」
数理計画法をやっている人間からすると、「それって、ちょっと、失礼じゃないの?」と思います。まあ、私も50代なので、印象を払拭する材料にはなりませんし、新しいものより、枯れた技術の方が、不具合も少ないし、事例も多いのでやりやすい、というのは、データサイエンスに限らず、良くある話ですが、「簡単か/難しいか」は、その問題によります。
数理計画法は、歴史的には古いかも知れませんが、ハードウェアの飛躍的な発展やアルゴリズムの向上によって、解ける問題の範囲は拡がっています。当然、新しい研究も行われています。理工系で「情報」を扱う学科なら、名称はともかく、今でも、普通にカリキュラムに組み込まれていますし、学んでいる方はたくさんいます。
SEをやっていた頃、システムを開発するだけでなく、お客さんや技術畑でない上司に対して、ITについて啓蒙することも大切な仕事でしたが、まったく知らない人を相手にするよりも、ちょっと聞きかじった人の方が厄介でした。これって、IT業界のあるあるだと思いますが。そういう厄介な人にならないで欲しいな、と思います。
●KADOKAWA「[図解]大学4年間のデータサイエンスが10時間でざっと学べる」久野遼平、木脇太一(2019/09)
東大の先生、お二人で書かれています。
「データ分析の基礎知識がこの一冊で身につく!」と帯にありますが、ハードウェアや、プログラミングの基礎から、統計学、ディープラーニングまで、結構、範囲が広く、内容は多岐に渡っています。
大学で学ぶ科目数でいうと、結構な数になるのではないでしょうか。
当然、とても、10時間で身に付けられるものではありませんが、ページ数は少ない(100頁に満たない)ので、10時間で読み終えることはできます。タイトル通り、大学4年間の内容をざっと見渡すことができる、というものですね。
この本も、例題を解いて読み進み、データサイエンスができるようになる、というよりは、教養本です。
大学4年間でどんなことを学ぶのか、知ることができる、といったところだと思います。
図解で一見読みやすそうなのですが、難解な言葉も結構出てくるので、これから学ぼうとする人、特に、文系の学生が理解するのは、ちょっとハードルが高いです。
一通りデータサイエンス系の学習をされた方が、どんな感じのことをやったか、振り返るのにいいのかな、と思います。
また、流行りのせいか、ディープラーニングについて、かなりのページ(27頁)が割かれています。
内容的にも、単純パーセプトロン、多層パーセプトロン、シグモイド活性化関数、RNNなど、ディープラーニングの概要だけでなく、さらに専門的な話へと続きます。
そこまで「(ディープラーニングだけに)深く知りたい」と思う人がいるのかも知れませんが、「文系だと、少ないかな」という気がします。まあ、この本は「文系」とは謳っていませんので、仕方ありません。ディープラーニング、理系の学生には人気があるのでしょう。
●ニュートンプレス「東京大学の先生伝授 文系のためのめっちゃやさしい 統計」監修 倉田博史(2021/04)
本のタイトルの通り、東大の先生が監修されている本です。
平均、分散、偏差値など、一つ一つ、すごく丁寧に書かれていて、とても分かりやすいと思います。これなら、中学、高校の数学で挫折してしまった人や、苦手意識を持っている人でも理解できるのではないでしょうか。
先生と学生の会話形式で書かれていて、こういうスタイルは冗長になりがちなのですが、やりとりの一つ一つがよく考えられていて、無駄がありません。先生の話題の振り方が、とても上手く、その先生の問に対しての学生の反応が、とてもリアルで、読者は、この学生に同調しながら、興味を持って、読み進めることができます。
扱っている題材も世論調査、生命保険、株、選挙の当落情報など、身近で、へぇーと思ようなものが多く、他の人にもネタとして話したくなるようなものばかり。読み物としても面白いです。
データサイエンスについて網羅されている訳では無いですが、データサイエンスで良く出てくる「相関」「t検定」など、しっかりと理解できると思います。
また、「疑似相関」など、注意すべき点も書かれていて、データサイエンスとはどういうものか、なぜ大切なのか、データサイエンティストとしての心構えも身に付けられると思います。
●オーム社「これだけは知っておきたい データサイエンスの基本がわかる本」鈴木孝弘(2018/03)
この本は東洋大学の先生が書かれています。
帯には、「これだけは知っておきたい基本事項」とありますが、その取り上げ方は、ちょっと独特です。
例えば、「第5章 多変量解析」、「第6章 遺伝的アルゴリズム」、「第7章 サポートベクターマシン」と並んでいますが、「多変量解析」は分野、「遺伝的アルゴリズム」は数理計画法などの数式を解くときの解法、「サポートベクターマシン」は機械学習のモデル、アルゴリズムですね。
一般的には、「多変量解析」や「遺伝的アルゴリズム」を階層的に分類するとすれば、こんな分け方になると思いますが...。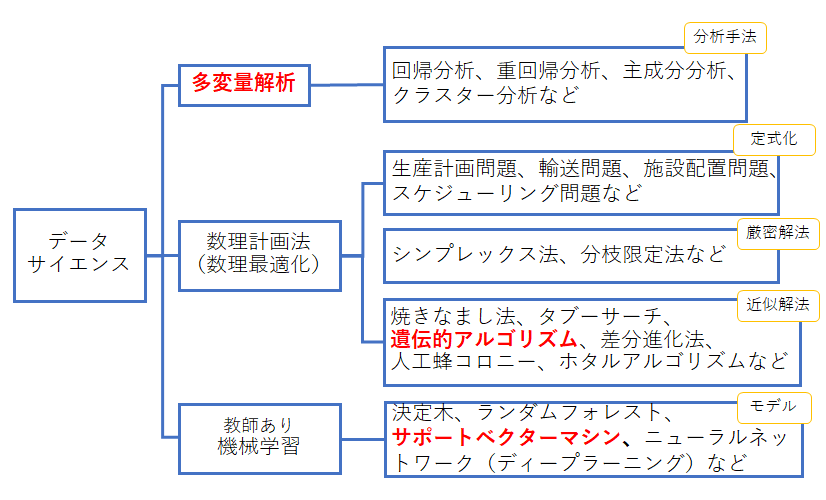
「ディープラーニング」が、章として扱われているケースは少なくないですが、「遺伝的アルゴリズム」や「サポートベクターマシン」が章として大きく扱われているデータサイエンス本は、珍しいと思います。
内容的には、やり方などが身につく実践的なものではなく、教養として読むものだと思うのですが、数式があったり、プログラムのフローチャートがあったり、本格的に踏み込まれている項目もあります。文系や初心者にはキツイかも。
体系的に学習したい、教養として身に付けたい、という方よりは、「とりあえず、学習してみて何かできるようになったけど、これってどういう意味なんだろう」という人や、「データサイエンスの教養本を読んで、こういう言葉が出てきたけど、これについて、もう少し知りたいな」という人が、辞書的に使うのに適しているように思います。
●実教出版「問題解決のためのデータサイエンス入門」監修 松田 稔樹、萩生田 伸子(2021/10)
著者は、東京工業大学や江戸川大学など、10名の先生方で、東京工業大学、埼玉大学の先生、お二人が監修されています。
さすが、専門性に特化した教科書やテキストを取り扱っている出版社だけあって、体系立てて書かれていて、学習しやすいと思います。
統計、多変量解析が中心で、機械学習までは含まれていません。でも、機械学習のアルゴリズムも「線形回帰」「クラスタリング」など分野的には多変量解析とリンクしていますし、機械学習の主な用途も、この本にも出てくる「識別」と「予測」なので、まったく関係ない訳ではないです。
例題に沿って話が進められていき、どのようなことに利用できるのか、どういう点に気を付けるのか、データサイエンスの基礎的な知識が身につきます。
文系の学生には分り難いところもありますが、数式ばかりが並んでいる訳ではないし、薄い(144頁)ので、読み切ることは出来ると思います。
実教出版のサイトから、データがダウンロードできますが、エクセルの操作手順や統計ツールについての説明はほぼ無いので、独学で利用するのは厳しいです。エクセルなどで実際にやってみると、より理解が深まると思うのですが、そこは先生がサポートしてあげる必要がありますね。
