GAIS主催:RAG 開発 セミナー・ダイジェスト ~「DifyではじめるRAG」森一弥氏(アステリア株式会社 エバンジェリスト)
2024年5月30日(木)の昼から、一般社団法人 生成AI協会(GAIS)主催の「RAG 開発 セミナー」がオンラインで開催されました。このセミナーでは、最初に、アステリア株式会社のエバンジェリストであり、生成AI協会のエバンジェリストでもある森一弥氏が「DifyではじめるRAG」というタイトルで講演を行いました。森氏はGAISの公式WebにDifyについて次の記事を投稿しています。こちらも参考にしてください。
■プログラムのいらないAI開発「Dify」のインパクト
https://gais.jp/dify-impact/
森氏のセミナーでは、RAG(Retrieval Augmented Generation)について詳しく説明しました。
 RAGの仕組みを理解するために、まずは基本的なフレームワークについて解説がありました。ユーザーが質問をすると、ベクターストアに保存されている類似データを検索し、その結果を踏まえてLLMが回答を生成するという流れです。このアプローチにより、より正確で関連性の高い回答が得られるようになります。
RAGの仕組みを理解するために、まずは基本的なフレームワークについて解説がありました。ユーザーが質問をすると、ベクターストアに保存されている類似データを検索し、その結果を踏まえてLLMが回答を生成するという流れです。このアプローチにより、より正確で関連性の高い回答が得られるようになります。
 次に、森氏はRAGの具体的な仕組みについて詳しく説明しました。まずは、RAGのデータベース(VectorStore)の準備について解説しました。企業や組織が保有するPDF、Word、Excel、HTMLなどのドキュメントを読み込み、分割してチャンクデータリストを作成します。このチャンクデータをベクター化し、VectorStoreに保存します。これにより、ドキュメントの内容が効率的に検索できるようになります。
次に、森氏はRAGの具体的な仕組みについて詳しく説明しました。まずは、RAGのデータベース(VectorStore)の準備について解説しました。企業や組織が保有するPDF、Word、Excel、HTMLなどのドキュメントを読み込み、分割してチャンクデータリストを作成します。このチャンクデータをベクター化し、VectorStoreに保存します。これにより、ドキュメントの内容が効率的に検索できるようになります。
 次に、類似検索と生成実行のプロセスについて説明がありました。
次に、類似検索と生成実行のプロセスについて説明がありました。
ユーザーが質問を入力すると、その質問に類似したデータがVectorStoreから検索されます。検索結果と質問を組み合わせたプロンプトを生成し、そのプロンプトをもとにLLMが回答を生成します。これにより、より関連性の高い回答を得ることができます。
 森氏は続いて、RAGを使用する理由について説明しました。RAGを導入することで得られる主なメリットは次の3つです。
森氏は続いて、RAGを使用する理由について説明しました。RAGを導入することで得られる主なメリットは次の3つです。
- 自社データは自社管理下に置ける
全データを外部に流さずに済むため、データのセキュリティが保たれます。また、VectorStore自体を複数用意することも可能で、データ管理の柔軟性が高まります。 - ベンダーロックインしない
LLMやVectorStore、設置する環境など特定のベンダーに依存しないため、自由にシステムを変更することができます。これにより、新しい技術が登場した際にも柔軟に対応できます。 - 最新技術への追従
AIモデルに革新的な性能向上があった場合など、該当箇所のみを変更することで、最新の技術を活用できます。これにより、常に最適なAI技術を活用することが可能です。
森氏はこれらのメリットを強調しながら、RAGがいかに企業のデータ管理とAI活用を効率化するかを解説しました。
 森氏は、最近注目が集まっているノーコード・生成AIツール「Dify」を紹介。Difyは、画面操作で生成AIのアプリを作れるプラットフォームで、オープンソースとして提供され、クラウド版とオンプレ版の両方が提供されており、VectorStoreも内部で連携しています。
森氏は、最近注目が集まっているノーコード・生成AIツール「Dify」を紹介。Difyは、画面操作で生成AIのアプリを作れるプラットフォームで、オープンソースとして提供され、クラウド版とオンプレ版の両方が提供されており、VectorStoreも内部で連携しています。
 森氏は次に、Difyを使用してRAG環境を準備する方法について説明しました。環境の準備には3つの方法があります。
森氏は次に、Difyを使用してRAG環境を準備する方法について説明しました。環境の準備には3つの方法があります。
- Cloud版
「https://cloud.dify.ai/」にアクセスし、GoogleかGitHubのアカウントでログインするだけで使用可能です。初回から無料で使用できるため、試してみるには最適な方法です。 - Docker版
コマンドを数回実行するだけでセットアップ可能です。AWS、GCP、Azureなど自社用の環境を用意することもでき、HTTPSアクセスを希望する場合には多少の工夫が必要です。 - ソースからデプロイ
Python、NodeJS、PostgreSQLなどの環境準備が必要ですが、自分の環境に合わせてカスタマイズすることが可能です。
 AWSでの環境構築の具体例が紹介されました。
AWSでの環境構築の具体例が紹介されました。
C5Large(2CPU)、Amazon Linux 2023、SSD 20GBのEC2インスタンスを使用し、スポットインスタンスでコストを節約しています。セキュリティグループで必要なポートを開放し、ロードバランサーとSSL証明書を設定することで、HTTPSアクセスが可能な環境を構築しました。
 EC2でのDockerインストール手順も具体的に示されました。
EC2でのDockerインストール手順も具体的に示されました。
SSHでログインし、DockerとDocker Composeをインストールします。これにより、EC2上でDifyを実行するための環境が整います。
 Difyの取得と起動方法についても説明がありました。
Difyの取得と起動方法についても説明がありました。
gitをインストールし、Difyのリポジトリをクローンして、Dockerを使用して起動します。ブラウザで初期設定を行い、管理者アカウントを設定することで、すぐに使用を開始できます。
 森氏は、RAG環境を構築する際に必要となるAPIの準備についても詳しく説明しました。
森氏は、RAG環境を構築する際に必要となるAPIの準備についても詳しく説明しました。
RAGを運用するためには、以下のLLM(大規模言語モデル)のAPIが必要です。
- OpenAIのAPI(ChatGPTの有料ライセンスとは別)
- Google Gemini
- その他
- APIが対応しているものであれば、ローカルに構築したものでもOK
さらに、連携したい各種ツールのAPIキーなどの設定も重要です。
- 用意されているツールのAPIキーを設定
- カスタムツールの場合は、OpenAPI(Swagger)形式の仕様書(JSONまたはYAML)を設定
- REST形式なら個別に入力も可能
これにより、様々なツールやサービスとの連携がスムーズに行えるようになります。森氏は、これらの設定を行うことで、より効率的にRAGを運用できることを強調しました。
森氏は、続いてDifyの実際の使用方法についてデモを行いました。
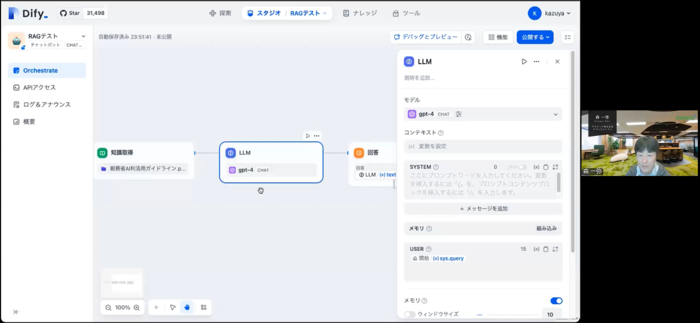 Difyの実際の使用方法
Difyの実際の使用方法

- Difyのログインと初期設定
まず、Difyのウェブサイトにアクセスし、GoogleまたはGitHubのアカウントでログインします。初回ログイン時には、管理者アカウントの設定を行います。これにより、Difyのダッシュボードにアクセスできるようになります。 - チャットボットの作成
ダッシュボードにログインしたら、新しいチャットボットを作成します。Difyのスタジオ画面から、「チャットフロー」を選択し、必要な名前と説明を入力してボットを作成します。 - ナレッジデータのインポート
作成したチャットボットに、ナレッジデータをインポートします。ナレッジタブから「知識を作成」を選び、PDF、Word、Excel、HTMLなどのファイルをドラッグ&ドロップでアップロードします。Difyはこれらのドキュメントをチャンクデータに分割し、ベクター化して保存します。 - プロンプトの設定
次に、プロンプトの設定を行います。ユーザーからの質問に対して、適切な回答を生成するためのプロンプトを作成します。ナレッジデータから検索した結果とユーザーの質問を組み合わせて、生成AIに回答を依頼する形にします。 - APIの設定
チャットボットが使用する生成AIのAPIを設定します。OpenAIやGoogle Geminiなど、利用するAPIのキーを入力し、連携を設定します。これにより、ボットが外部のLLMを利用して回答を生成することが可能になります。 - テストとデバッグ
設定が完了したら、デバッグとプレビュー機能を使ってボットの動作を確認します。テスト用の質問を入力し、生成される回答を確認します。必要に応じて、プロンプトやナレッジデータの設定を調整します。 - 公開と利用
チャットボットが正しく動作することを確認したら、公開して利用を開始します。公開されたボットは、ウェブサイトに埋め込んだり、Chromeの拡張機能として利用したりすることができます。
森氏のデモを通じて、参加者はDifyを使用してRAG環境を構築する具体的な手順を理解することができました。
森氏はセミナーを次のように締めくくりました。「RAGの導入は、企業や組織にとって大きな可能性を秘めています。データの管理や活用方法を工夫することで、業務効率の向上や新たなビジネスチャンスの創出が期待できます。Difyを使えば、簡単にRAGを実装し、自社に最適な形で運用することが可能です。導入に際して困ることがあれば、ぜひご相談ください。皆さんが生成AIの可能性を最大限に引き出せるよう、全力でサポートいたします。」