日常のマーケティング IT - Excel データマイニング編 その 5 - シナリオ分析による実績値に基づくシミュレーション
さて今回は、「シナリオ分析」 機能を試してみよう。この機能は 「ゴール シーク」 と 「What-if」 の機能オプションを持っている。ゴール シークとはその名の通り、特定の列 (対象列) の目標値がわかっている場合に、他の列 (変化させる列) がどのように変化すればその目標値を達成できるかを知るためのもの。一方の What-if はその逆方向で、ある列での変更が他の列の値に及ぼす影響を測定するためのものだ。たとえば、「ある商品を購入する可能性を高めるためには、購入者の年収は幾ら以上であればいいのか」 を知るのがゴール シークであり、「購入者の年収が20%上がった場合は商品を購入するようになるか」 を知るのが What-if なのである。
実は、Excel の標準機能としても同一名称のツールが用意されている (「データ」 タブの 「データ ツール」 内) のだが、その機能ではあくまで、予測可能列と入力列の関係性を関数として定義しないと、目標達成のための値を見つけ出すことができない。つまり、厳密には予測しているわけではなく、値を当てはめて網羅テストしているのだ。
ロジスティック回帰による確率分析
それに対しこのツールは、マイニング アルゴリズムを使って、値を推定することでちゃんと予測しているのが、大きな違いである。この機能では、SQL Server Analysis Services に搭載されている 「Microsoft ロジスティック回帰」 アルゴリズムが使っている。ゴール シークも What-if も、方向が違うだけなので同じアルゴリズムを使う。
「ロジスティック回帰」 とは、「ロジスティック曲線」 を用いた回帰分析のことを言う。いわゆる通常の 「線形」 回帰では、たとえば生物の個体数と増殖速度の関係性を分析したとすると、個体数が増えれば増えるほど等比級数的に (いわゆるネズミ算式に) 増殖速度が増すという結果が算出されることになる。しかし現実には、個体数増加に伴う食料不足の発生などを理由として、その速度はあるピークを境に逓減するため、回帰曲線は直線ではなく S 字を描くことになるはずなのである。この S 字曲線がロジスティック曲線であり、それを使って確率を推定するのがこのロジスティック回帰だ。このアルゴリズムを用い、期待される予測可能列の状態に対して、入力列が影響を与える確率を計算できる。
「シナリオ分析」 機能では、このアルゴリズムを用いてテーブル内のデータを分析、ある列の値が別の列の値に影響を与える確率を計算し、その確率がもっとも高くなる値を探る。ゴール シーク オプションでは、ある列の値が目標値達成に近づくための、別の列の値がとるべき推奨値とその達成の可能性を算出する。一方 What-if オプションでは、ある列の値が変化した場合に、別の列がとる可能性の高い値とその信頼度を算出する。
では試してみよう
では、Data Mining Add-in に付属のサンプルデータで試してみよう。Windows スタートメニューの [すべてのプログラム] - [Microsoft SQL Server 2012 データマイニング アドイン] - [Excel サンプル データ] を開き、「Table Analysis Tools Sample」 シートを選択する。このシートは既に何度か使ったが、いわゆる顧客情報テーブルで、既婚/未婚、性別、収入などの個人プロファイルと、その個人が Purchased Bike (自転車を買ったか買っていないか) を示すフラグが入力されている。表をクリック、「テーブル ツール」 の 「分析」 リボンにある 「シナリオ分析」 ボタンをクリックすると、「ゴール シーク」 と 「What-if」 のいずれかが選択できるようになっている。まずは 「ゴール シーク」 をクリックすると、同名のダイアログ ボックスが表示される。
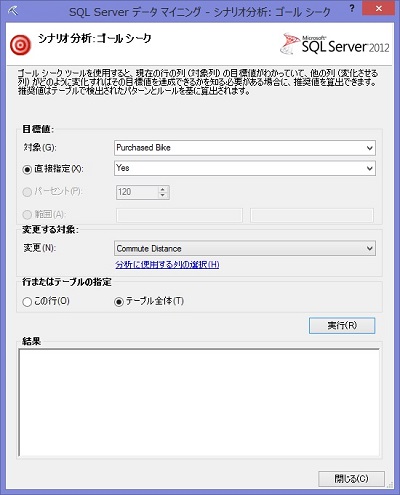
目標値の 「対象」 を "Purchased Bike" にし、目標値の入力は 「直接指定」 で "Yes" にしてみよう。さらに、「変更」 する対象の列を "Commute Distance" にしておく。これで、Purchase Bike 列の値が Yes になるために Commute Distance がとるべき値をテーブル全体にわたって分析してくれるようになる。なお、「分析に使用する列の選択」 オプションで、テーブル全体のパターン分析を行う際に取り入れる列を選択できる。列が多いほど分析に時間がかかるので、Purchased Bike 列の値とは明らかに関係のないと思われる列は省いてかまわないが、ここではデフォルトのまま、すべて選択されている状態にしておく。また 「行またはテーブルの指定」 で 「この行」 だけを分析するようにした場合、現在選択されている行のみの分析結果が、ダイアログ下部の 「結果」 ボックスに表示されるが、ここでは 「テーブル全体」 を選択しておく。これで 「実行」 ボタンを押すと分析が始まり、その完了とともに、既存列の右側に分析結果が追加される。
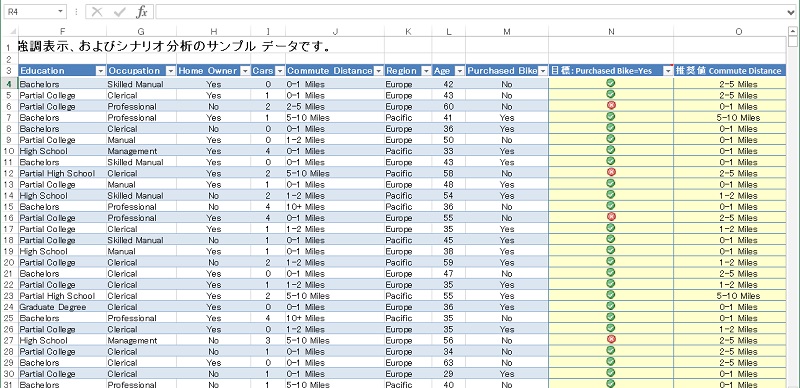
N 列に 「目標: Purchased Bike=Yes」 が、O 列に 「推奨値 Commute Distance」 が追加された。各行での Commute Distance 列の値が 「推奨値 Commute Distance」 の値であることが、Purchase Bike=Yes になる可能性がもっとも高くなることを示している。ただし、「目標: Purchase Bike=Yes」 列に赤い×マークがついている場合は、そもそもこの目標を達成する可能性が薄いことを表している。
では次に、このまま What-if もやってみよう。表をクリック、「テーブル ツール」 の 「分析」 リボンにある 「シナリオ分析」 で今度は 「What-if」 をクリックする。
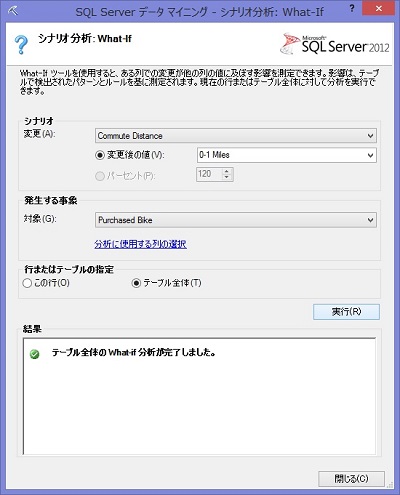
シナリオの 「変更」 を "Commute Distance" にし、「変更後の値」 を "0-1 Miles" を選択。「発生する事象」 の 「対象」 は "Purchased Bike" にし、「行またはテーブルの指定」 は 「テーブル全体」 を選んでおく。これは先ほどのゴール シークとまったく逆のこと、つまり Commute Distance の値がもし 0-1 Miles に変化した (もちろん変化しない行もあるが) としたら、Purchase Bike が Yesと No のどちらになるかを推定することになる。これで 「実行」 ボタンを押すと分析が始まり、その完了とともに、テーブルのさらに右側の列に分析結果が追加される。
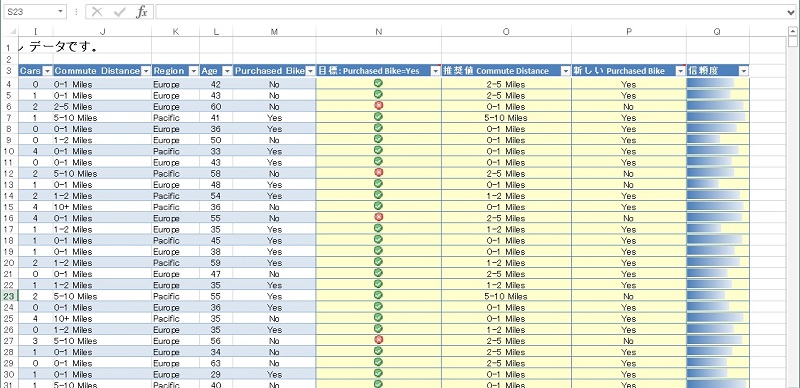
P 列に 「新しい Purchased Bike」 が、Q 列に 「信頼度」 が追加された。各行で Commute Distance 列の値が 0-1 Miles に変化した場合に Purchase Bike がどうなるか、そしてその推定の確からしさを示している。信頼度は値で計算されセルに含まれているが、表示上は条件付書式のデータバーで表現される。
このようにシナリオ分析は、各列の値に基づき求められるパターンから確率を推定することで、その確率が最大になるような値を特定するという、シミュレーション機能を提供してくれる。購買率や故障率などの推定のような、非常に多くの要因を持つために事前の関係性 (=関数) の定義が難しいデータの場合、それぞれの実績をもとに関連性を推定するこの手法は、非常に便利で高い効果を示すはずだ。
@hirokome on Twitter