生成AI勉強会まとめ:園田智也氏「インフラ化される智能:Transformerの技術的背景と今後」(アステリアART 代表)
2023年5月10日(水)に開催された「第2回 GPT / ジェネレーティブAI 勉強会」において、アステリアARTの園田智也博士が「インフラ化される智能:Transformerの技術的背景と今後」と題して講演をされました。
当日は、Zoomウェビナーにより配信が行われました。その録画ファイルから音声を切り出し、OpenAI社の提供するWhisperにて文字起こしをして、ChatGPTと壁打ちしながら、本稿を書き上げました。

園田氏は、普段は、早稲田大学の非常勤講師として、情報系の学生を指導しながら、Asteria ARTでは、AGIを見据えたAIとRoboticsの研究開発を行ってきたそうです。
ここで、AGI(汎用人工知能/Artificial General Intelligence)とは、従来のAIとは異なり、高い知能を持ちつつも人間のような思考や感情の理解が可能になったAIのことで、これにより、人間の感情に対する理解と共感を持ちながら、独自の行動を選択することができると言われており、従来のAIは特定のタスクに特化した知識を持ち、それを実行するのが得意でしたが、AGIはその汎用性から、さまざまなビジネス領域でも活用される可能性が広がっていると言われています。
講演の冒頭、園田氏は「皆さんは、なぜこんなに気がついたらAIと一緒に働いている世界になっているんだろうと思っているかと思いまますが・・・」と、技術的な背景の説明に入られましたが、日々、この生成AIと関わっているとまさしくその感はあり、それまでのAIって「向こう側」にあるものだったのが、いきなり「こちら側」に来ている感覚はあります。

以前は、ディープラーニングがAIの中心で、大量のデータセットが必要であったために画像認識の分野は、大変な作業だった。2012年以降、事前学習や転移学習の手法が画像認識に普及したが、言語モデルの場合はこの課題を解決するのが難しく、長らく困難であったとされています。
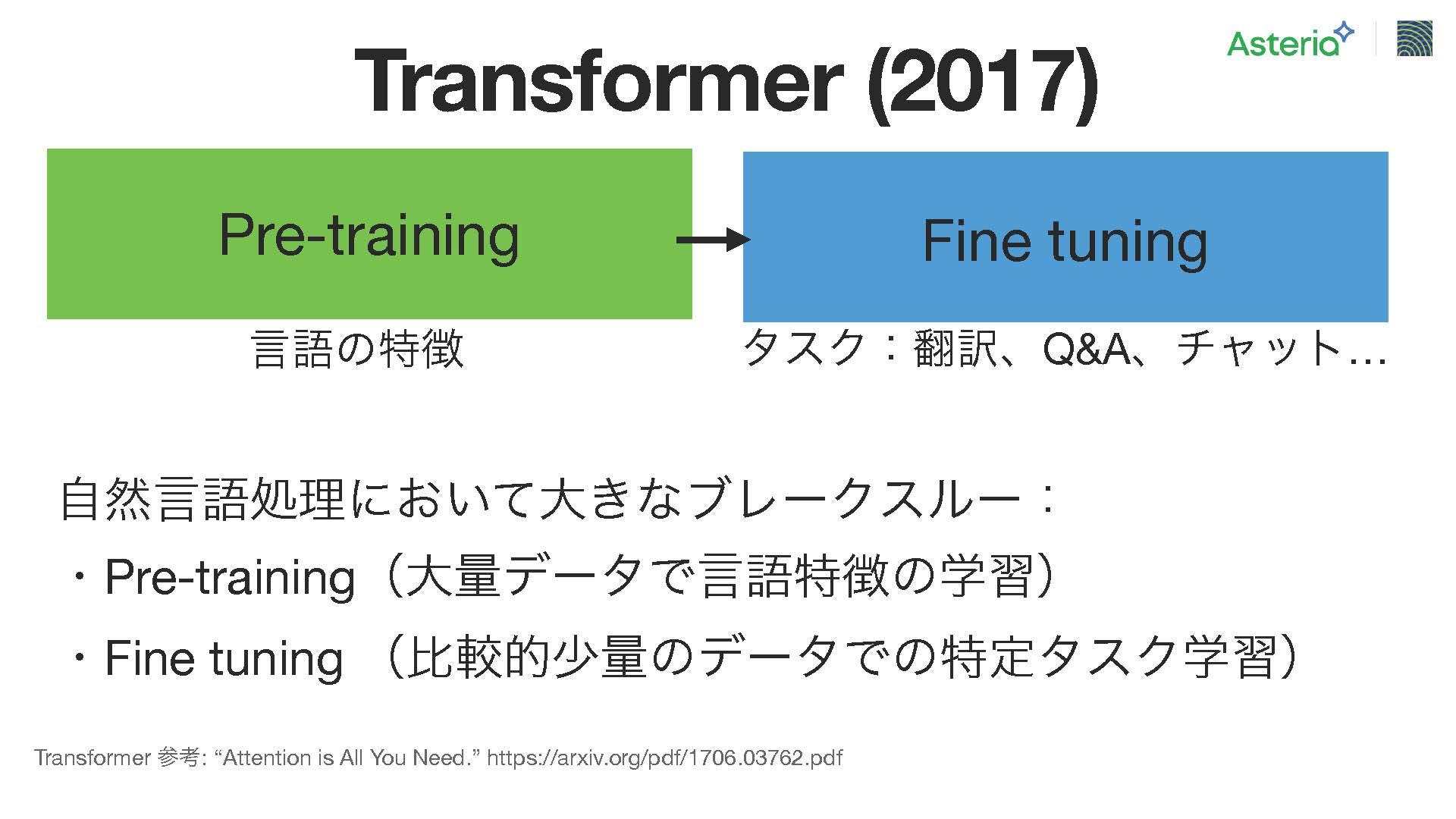
そこで登場したのが、Transformerという技術で、この技術は2017年に発表され、言語の特徴を学習する『プレ・トレーニング』という機能、そして『ファイン・チューニング』という2つの機能が特色だそうです。その結果、上の図の緑色の部分、プレ・トレーニング段階では、言語ごとにどのような順序で言葉が使用されるか。例えば日本語であれば、どの単語がどの位置に来るか、あるいは英語であればどのようなルールがあるか、といった言語の特徴を学習したモデルを使用して、右の、わずかなファインチューニングデータセットを用いてモデルを微調整することができるようになったのですが、このアプローチが様々な課題に対して有用であることが明らかになったそうです。このような革新的な手法が、多くの課題に対して有益であることから、大きな転換点となりました。と、園田氏は強調しました。
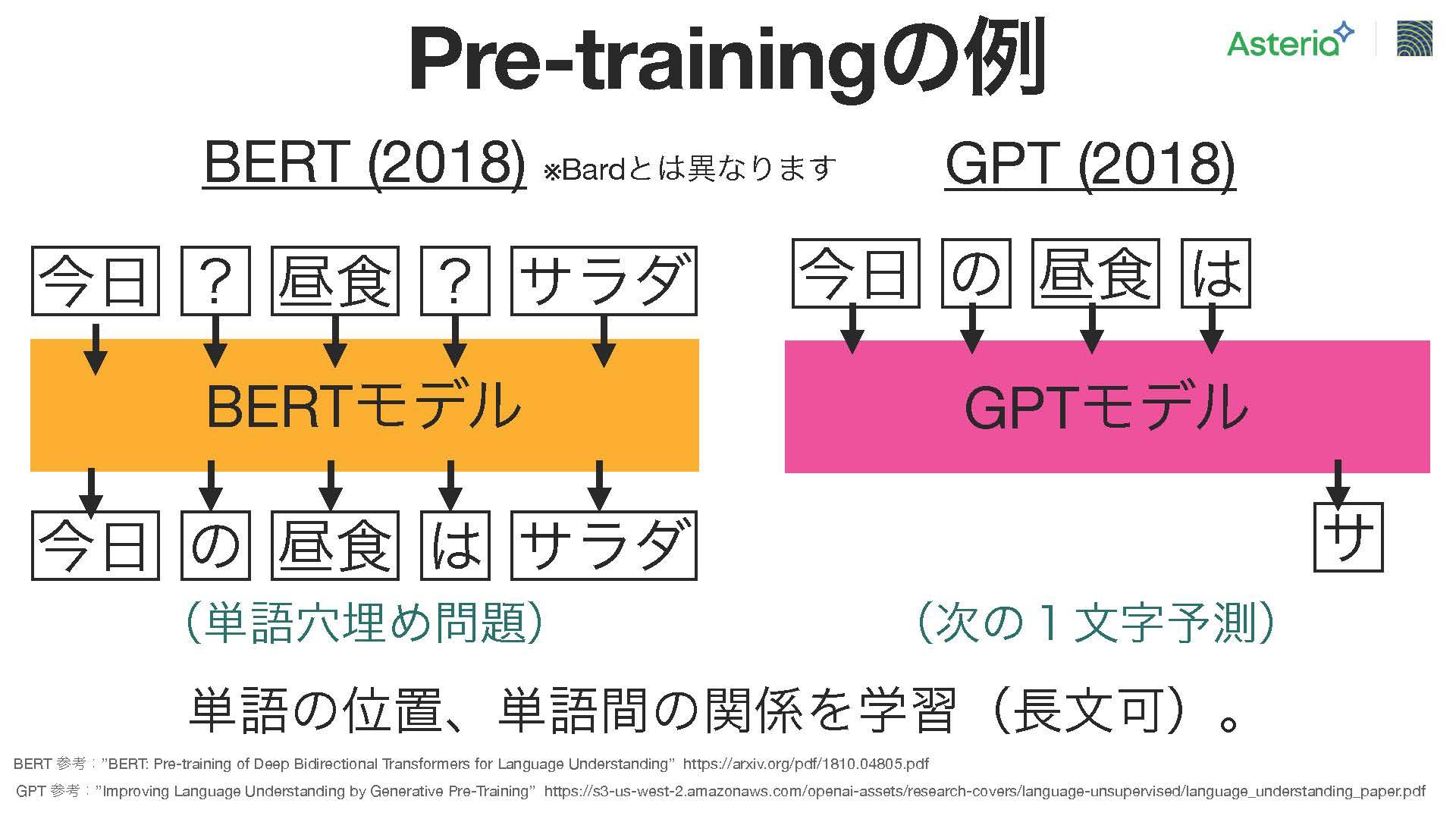
2018年に、この手法を活用した大規模モデルが2つ登場し、それが、バートとGPT。バートは、Googleによって開発された言語モデルで、単語の予測課題を解くために使用され、バートモデルでは、例えば「今日の天気は晴れ」という文の中から一部の文字を意図的に隠し、それを予測する学習が行われる。このモデルにはTransformerアーキテクチャが応用されており、文字の予測を行う仕組み。
一方、右側のGPTは、ChatGPTの基盤となるモデルで、与えられた文脈から次の1文字を予測する。具体的には、トークンと呼ばれる単位ごとに処理され、例えば「今日の天気は」と入力すると、その次に来る文字を予測します。このモデルもまたTransformerアーキテクチャを活用しており、自動化された学習を実現している。
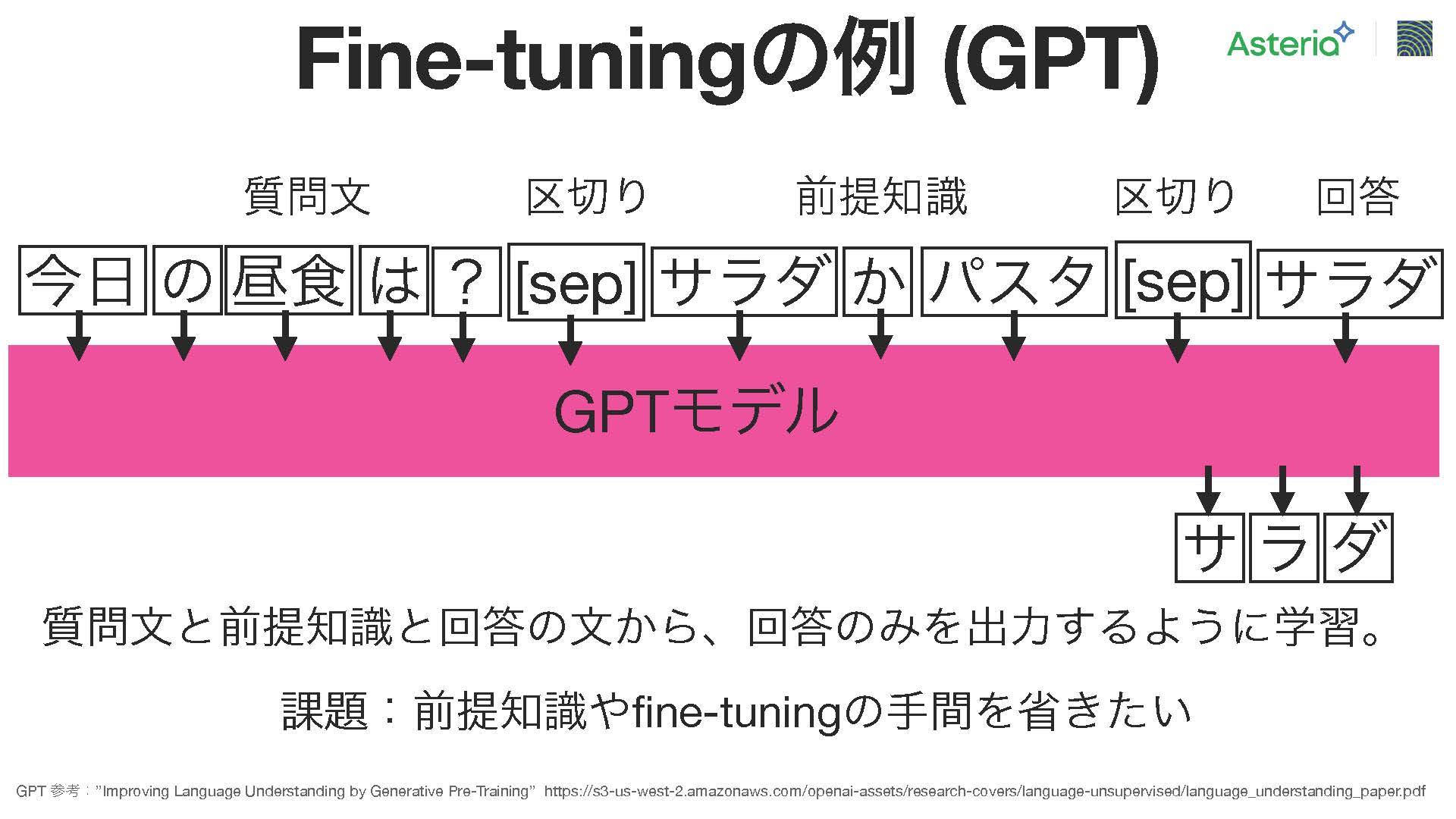
こうしたプレ・トレーニングの後、単語の関連性や位置関係を考慮して、ファイン・チューニングを行う。GPTにおけるファイン・チューニングの一例として、次のようなケースを考えてみる。質問文「今日の昼食は?」に対して、回答として「サラダ」を生成するモデルを構築したいとする。この場合は、次の手順で学習を行う。
まず、「今日の昼食は」までの文脈情報や、サラダやパスタなどの選択肢を含む世界知識を入力としてモデルに与えます。そして、「今日の昼食は」の後に「サラダ」という回答文を結合し、モデルが「今日の昼食は」を入力されたときに「サラダ」という適切な回答を生成できるように学習させる。このようなアプローチによって、様々な質問に対しても適切な回答を生成する能力をモデルに身に付けさせることが可能。
ただし、ここでも課題が存在する。ファインチューニングのための適切な文書を生成する作業は手間がかかる。前提知識を適切に組み込むことや、1000個や2000個の文を作成するだけでも多くの手間がかかることがある。

そこで、GPT-2の進化において、データセットを拡大し、モデルのパラメーターを増やすことによって、より常識的な出力を得る試みが行われた。これが「コモンセンス・リーゾニング」と呼ばれるものだ。
例えば「子供と大人、どちらが腕が強いですか?」という質問を考えてみる。通常、私たちは大人の方が強いと答える。その背後には、大人の筋力が子供よりも高いという事実がある。同様に、GPT-2にも同じ質問をすると、大人の筋力が子供よりも高いという裏付けを持つ回答が得られるようになる。こうしたリーゾーニングによって、より適切な回答が生成されることが明らかになった。
この進化によって、次にどれだけモデルを大きくすべきか、どれだけ大規模なデータセットが必要かといった課題が浮上してきた。ただし、単純にモデルを大きくするだけでなく、エネルギーやコストといった問題も考慮しなければならない。これに対処するためには、将来の展望を考慮した予測が必要であり、これが今後の課題となっている。

ここでOpenAIのチームが重要な発見をしました。スケールと速度の関係に関するもので、特にトランスフォーマーを使用した言語モデルにおいて顕著です。画像モデルにも当てはまる部分ですが、訓練時間、データセットサイズ、およびモデルのパラメーター数を増やすと、学習の結果の誤差が減少しやすくなる法則が見出されました。つまり、データ量を100倍に増やすと、誤差が効果的に低減することが観察され、グラフでも確認できます。
さらに、彼らの重要な発見の一つは、パラメーターやデータセットサイズ、計算資源などをどのような割合で増やせばいいかを計算する能力でした。この計算を通じて、パラメーターを増やすことで精度が向上する効果が明らかになりました。さらに、パラメーターの増加に伴う限界点や安定性についても予測が行われました。現在、一般的に使用されているモデルは約5千億のパラメーターまで増やしても問題ないことがわかっており、それを超えるとやや安定性に影響が出る可能性があるとされています。

次のGPT-3では、マイクロソフトとOpenAIは協力してAIスーパーコンピューターを構築した。このプロジェクトでは、28.5万台のCPUコアと1万台のGPUを結びつけて利用するというニュースが報じられている。そして、この投資の結果、GPT-2にスパス・トランスフォーマーと呼ばれる少し計算を省略化できるトランスフォーマーを追加し、さらにデータセットを拡大することで、ファインチューニングが不要なモデルをある程度まで構築することが可能となりました。このモデルは、すでに学習済みの世界知識をもとに推論して回答するスタイルを持っています。
例えば、「リンゴはアップル、ではバナナは?」という質問に対して、最初の部分から「これは英訳文だな」と推測し、リンゴがアップルであるならばバナナに対する英訳文を出せばよいという風に、推論を行う仕組みがある。これをフューショット・ラーニングと呼び、いくつかの例示を通じて学習を進めていくことで、ゼロショットやワンショットといったスタイルも実現している。こうした推論の能力は、ChatGPTの技術として活用されている。ただし、ChatGPTはこれだけで機能するわけではなく、入力の前処理と出力の後処理も含まれている。また、出力の前処理には多くのコストがかかっており、人間のフィードバックを受けながら強化学習を組み込むことで、AIアライメント問題と呼ばれる大きな課題に取り組んでいる。この課題は極めて重要であり、以前は、人間の意図しない回答を生成してしまうことがあったが、そのような側面を補正し、人間の常識の範囲内に収めるコントロールを行うことを成功させた。さらに、事実の歪曲や虚偽の情報を軽減し、一般に公開可能な安全性とバイアス性に配慮して公開した。
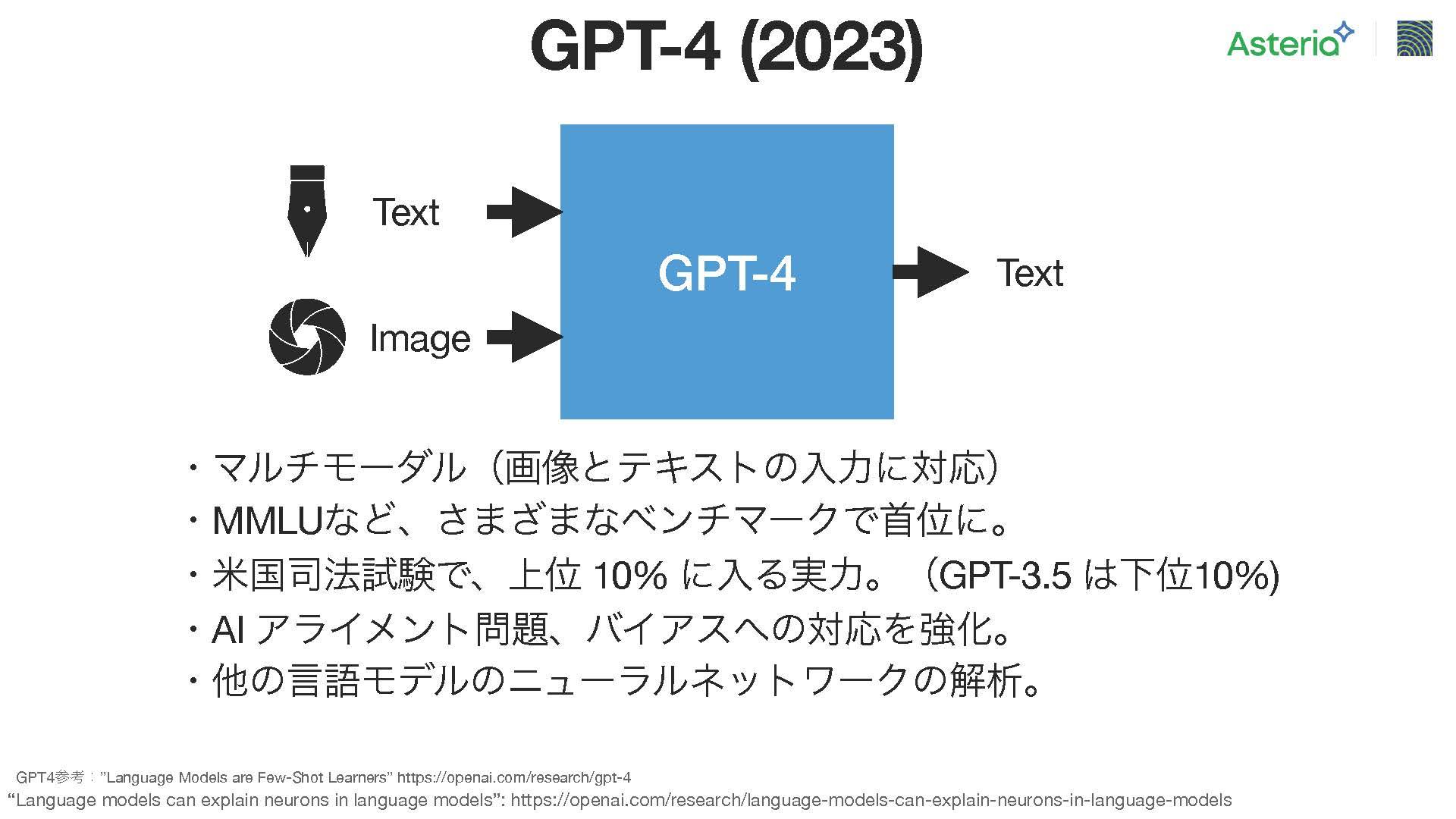
続いて、GPT-4が登場。詳細な技術情報はまだ公開されていないが、広く知られていることは、マルチモーダルな対応能力を持っているという点。具体的には、テキストとイメージを組み合わせて入力すると、テキストを生成する能力を持っている。ただし、画像の側についてはまだ限られた企業しか利用できない状況。
また、様々なベンチマークテストも行われており、英国の言語試験などでは上位10%にランクインするほどの実力を示している。以前のGPT-3や3.5では下位10%に位置していたのが、GPT-4では大幅に向上しており、日本の医師国家試験に合格したニュースもあり、この技術の高い性能が確認されている。
さらに、AIアライメント問題やバイアスに関する対応も強化されており、他の言語モデルのニューラルネットワークの解析にも応用されている。

ここまで急速に進展してきたが、今後の展開については、まず「ファウンデーション(基盤)モデル」という概念が注目されている。これは、言語モデルとして巨大なパラメータを備えたものを基盤とし、イメージとしては、ロボットが床に基盤を置く様子にたとえられていて、多様なタスクに活用するアプローチを指している。例えば、Stable Diffusionのような Text-to-Image でイメージを生成するものや、Text-to-3D で DreamFusionとかShap-Eだとか、あとは Text-to-video も現れており、ビデオ動画の生成も可能となっている。

さらに、ロボットの分野においても、ChatGPTが空間を認識できることからロボットの行動パターンに利用されている。最近登場したUniPiという技術が注目されていて、例えば、YouTubeの動画などを学習させ、テキストを与えて動画を生成させ、その後にロボットの動く環境と画像を結び付け、ロボットに対する指示に従って動作を行うビデオを生成する。例えば、オレンジのブロックを赤いブロックの隣に置くようにと指示された場合、ロボットがブロックを移動させるビデオを生成する。このプロセスにより、ロボットの動作を計算し逆接的にプランニングすることが可能となる。逆運動学やインバースキネマティクスの原則を活用して、ロボットの運動を逆算する。このようなアプローチは、例えば昨年から提案されている PaLM-SayCan のような画像関連のモデルとも連携し、さまざまなタスクを同時に学習させることで、この分野で広範な成果が得られる可能性がある。
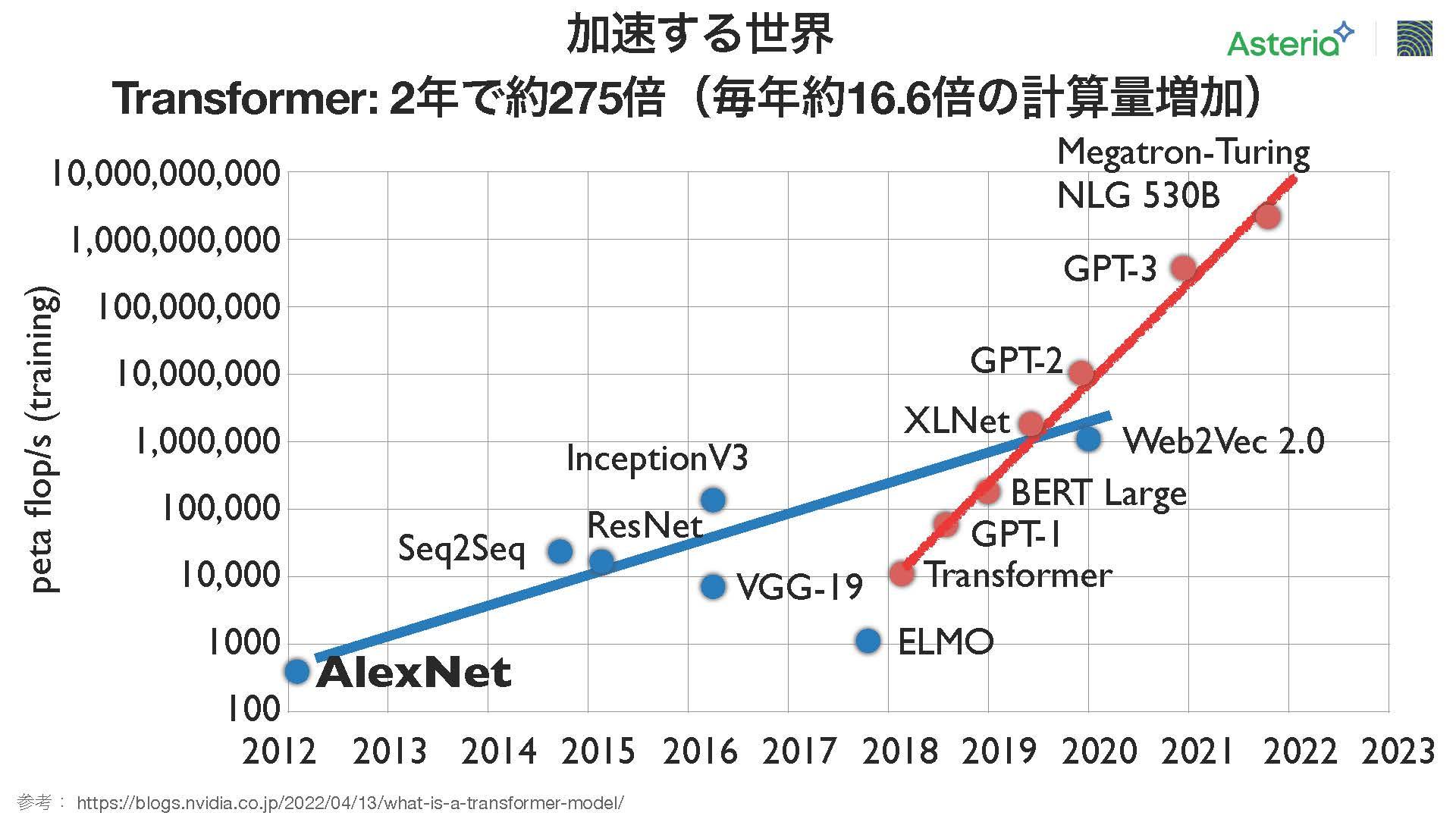
計算量については、急速に増加しており、こちらはNVIDIAが去年公開したグラフを改変したもの。たった1年で計算量が約16倍に増加している。主要なモデルでも、昨年のトップモデルと比較して16倍ずつ計算量が増えている傾向がある。この業界の進展速度は驚異的であり、特に赤いラインはトランスフォーマーをベースにした技術を示しており、
これまでの技術と比べて計算量が急速に加速していることが分かる。
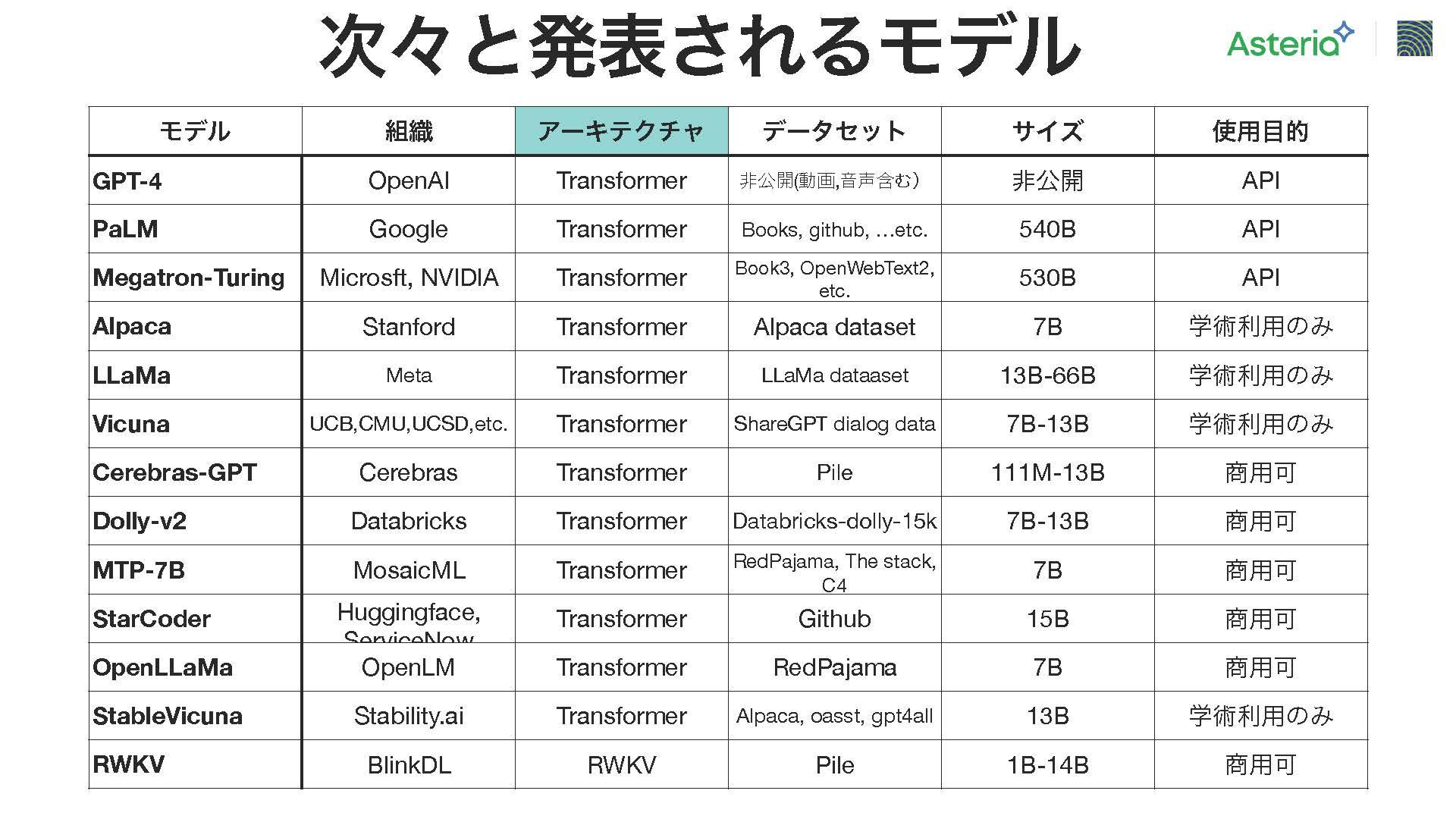
ほぼ毎週のように新しいモデルが提案されており、ここにピックアップしているのはごく一部(2023年5月10日当時)だが、提案されているモデルの多くはトランスフォーマーベースのアーキテクチャを採用している。また、今後の展望としてRWKVという別の高速技術が存在し、非常に有望なものとされている。現時点ではトランスフォーマーが広範なモデルで使用されている状況。初期の段階では主に学術的な利用が主流だったが、最近では商業用途のモデルも増えてきているという状況。
直面する課題
こういった急速な技術の進展に伴い、さまざまな課題に直面することになる。ここでは3つの課題に焦点を当ててみる。
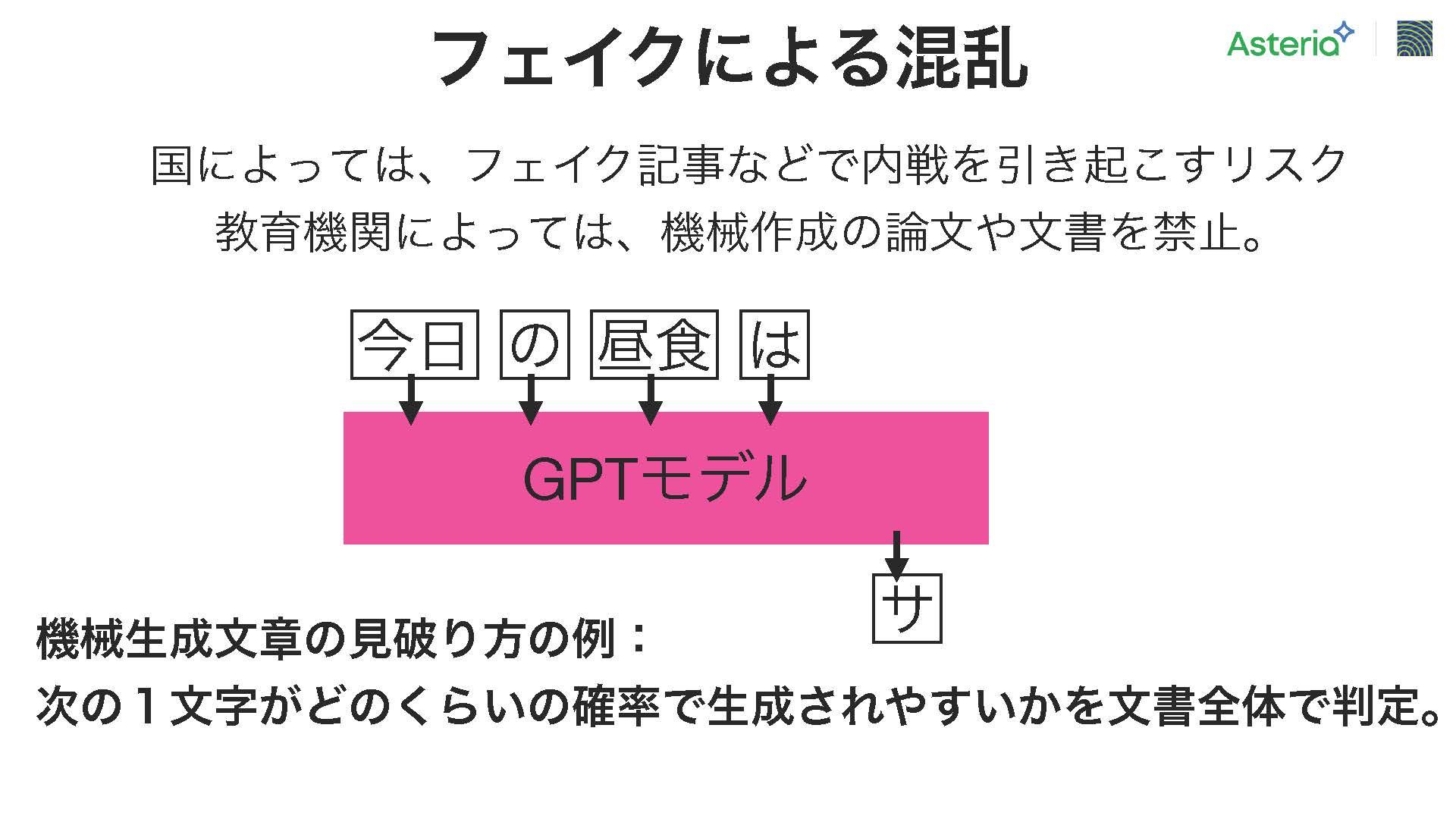
まずは「フェイクによる混乱」である。特に選挙などの場面で、相手候補に対して虚偽の情報を広めることで、投票者の意向が影響を受け、対立候補に投票するケースが問題視されている。ここ数年で注目されており、今回の言語モデルでは、非常に簡単にフェイクニュースを生成できる可能性があるという点が懸念されている。また、大規模な国家的な問題だけでなく、最近では教育機関でも同様の課題が浮上している。例えば、機械によって生成された論文やレポートの提出を禁止とするケースが増えている。
こうした問題に対処する一つの方法として、GPTモデルでは次の1文字を予測することができることから、ある文書が与えられた場合、それまでの文書から各文字の予測確率を計算し、
次の文字がどれだけ予測しやすいかを評価することがでる。これを活用することで、文書全体を通して次の文字の予測確率を集計し、機械生成による可能性を評価することができる。
例えば、文書内の多くの文字が言語モデルから生成されやすい場合、その文書は機械によって作成された可能性が高いと判断することができる。このようなアプローチを用いたサービスも登場しており、文字単位の予測確率を活用して判定を行っている。

次に、画像ではどうでしょうか。左側は通常の写真サイトから取得したテニスプレイヤーの画像であり、右側の画像は DALL-E と呼ばれる生成モデルによって生成されたもの。これを見分けるための一つの方法は「クラスタリング」と呼ばれる手法。この手法では、画像内のRGB値を幾つかのグループに分割し、それぞれのグループに対応する色で画像を塗りつぶす。この塗りつぶしはランダムに行われるが、左側のテニスプレイヤーの画像ではラケットの裏側が壁の隙間として描かれており、そのままネットの部分に続いている。しかし、右側の男性の画像では同じ部分に背景の隙間が表に出ていないことがわかります。これによって、別々の生成ロジックによって画像が生成されたことが分かる。
あとは、女性の腕の部分には「肌の等高線」と呼ばれるアニメでよく見られる特徴があります。しかし、このような特徴を持つ画像は、生成モデルを用いて作成する際には出現しにくい傾向があります。

2つ目の課題として、人類は今後しばらくの間『人間ならではの仕事は何か?』という問いに直面していると考える。このテーマは古代ギリシャの哲学者アリストテレスの時代から議論されており、彼の著書『政治学』の中で触れられている。当時の社会では奴隷制度が存在し、奴隷は「生きた道具」と見なされていた。奴隷と非生物の道具の違いが、その働きから来るものであり、もし非生物の道具が自動的に作業を行ったり音楽を奏でたりできれば、奴隷は労働から解放される可能性があると主張している。
このアイデアが実現したのは産業革命の時代であり、人々は労働から解放される一方で、機械による大量生産や仕事の自動化が進み、失業者が増える結果となった。この現象により、労働者たちは機械を破壊する「ラッダイト運動」などを起こした。また一方、大量生産によって、一般の人々も製品を購入できるようになった。その製品を販売するためのサービス業が発展し、多くの人々がサービスを提供する仕事に従事するようになった。
そして現在、AI技術と機械学習技術によって、再びサービス業が自動化される可能性が浮上している。これにより将来的に人々がどのような仕事をするべきかという問題が再び浮かび上がってきている。これに対する一つの解答は、多くの人が情報分析やAI技術の活用に従事することであり、これによって新たな価値が生まれると考えています。情報産業やAI産業に関するスキルが育成されることで、人々は自身の仕事を見つけ、解決策を見出すことができると、園田氏は強調した。

課題の3つ目として、最近よく取り上げられているのが、近い将来にスーパーインテリジェンスが現れる可能性と、それに伴う懸念だ。スーパーインテリジェンスとは、人間の知能を遥かに超えたAI技術のことで、その出現が間近に迫っているのではないかと心配されている。一旦アーティフィシャル・ジェネラル・インテリジェンス(AGI)が実現すると、初めは人間の知能を模倣するフェーズを経て、その後は自己改良を繰り返して急速に進化する可能性がある。たとえば、ChatGPTのようなAIが自らのソースコードを改良することは、おそらく容易に実現できるだろう。しかしながら、その自己改良の速度が極めて高速であるため、驚くべき知能を持つスーパーインテリジェンスが急速に出現することになるかもしれない。この新たな知性が持つ力や可能性は、アインシュタインやニュートンのような偉大な人物とは比較にならず、人間と昆虫の知性差ほどの大きなギャップを持つものとなるかもしれない。このような状況において、人類の未来や存続が脅かされるのではないかという懸念が存在している。
同様に、こういった高度な知性をコントロールできる主体が出現する可能性も考えられていいる。たとえば、特定の組織が株式市場を操作するなどの事例が挙げらる。このような力を持つ組織が登場すれば、その影響力は巨大で、経済や社会に大きな変革をもたらす可能性がある。これらの課題は、AIの進化がもたらす影響に対する議論や対策を考える上で重要な要素となっている。

こうした課題は幾つか存在するが、園田氏は、未来に向けて知能はまるで水道をひねるような手軽さで身につくインフラとなると主張している。さらに、これは何を意味するかというと、個々の人々の能力が劇的に向上し、可能性が広がっていく時代に突入し、この新たな時代は、人々にとって非常に希望に満ちた展望をもたらすものとなると強調した。