AIが自然言語を"理解"する仕組みとは? 文化系のための人工知能入門 "第7回"
最近「自然言語を理解するAI」という言い方をよく聞きます。これはAIと呼ばれている技術で出来ることを直感的に分かりやすく説明する良い表現ですが、同時に誤解を生みやすい表現だと筆者は感じています。
"理解"という言葉の意味を辞書で引いてみましょう。
1 物事の道理や筋道が正しくわかること。意味・内容をのみこむこと。「理解が早い」
2 他人の気持ちや立場を察すること。「彼の苦境を理解する」
出典:デジタル大辞泉(小学館)
"理解"という表現を額面どおりに受け取ると「自然言語を理解するAI」というのは、『人間の言葉を正しくわかって、気持ちを察してくれる』まるで鉄腕アトムやドラえもんみたいなロボットを想像してしまいますが、そんなものは存在しません。
では"理解"はどういう意味で使われているのでしょう?自然言語を扱う以下のような処理をコンピューターが行うことを、擬人化して「自然言語を"理解"するAI」と表現しているというのが実際のところです。
- 機械翻訳 (例)日本語を英語に翻訳
- 文書分類 (例)Webの記事をスポーツ、政治、etc、、とジャンル分け
- 文書要約 (例)長い文書を短く要約
- 質問応答 (例)言葉を使った質問に答える
- 対話 (例) チャットボット、Siri
AIはこうした擬人化した表現で語られることが多いので注意が必要です。AIの技術を正しく理解するためには、擬人化した表現が表していること「実際どんな処理を行っているのか?その仕組みで出来ることは何なのか?」を把握しておくことが大事です。
今回は「自然言語を理解するAI」と擬人化して語られる処理の代表である機械翻訳を例に、具体的にどんな仕組みなのか、その概要をご紹介します。
ディープラーニングを使った機械翻訳
コンピューターを使って翻訳を行う処理を機械翻訳と言います。機械翻訳は昔から研究されており、時代によって色々な実装方法が考えられてきました。
この1〜2年で脚光を浴びているのがディープラーニングを使った機械翻訳です。ディープラーニングは機械学習の手法の一つで、従来の手法では実現できなかった高い翻訳精度を実現して注目されています。
(ディープラーニングの概要はこちらの記事を参照ください)
ディープラーニングを使った機械翻訳では "ニューラル翻訳" という仕組みが使われています。Googleの翻訳サイトはこの仕組みを採用して劇的な精度向上をしたと言われています。
Googleの翻訳サイトをまだ使ったことがない方は是非試してみてください、驚くほど流暢な翻訳をしてくれますよ。
ニューラル翻訳ではまず大量の対訳データ(日本文と英訳文のセット)を使って学習を行います。"学習"というのも擬人化した言い方ですね、大量の対訳データを使ってニューラル翻訳のパラメーターを適切な値に設定することを "学習" と言っています。学習が完了した後に日本語を入力すると英訳文を出力してくれます。
今日はいい天気です → It is fine today
ではここから実際にニューラル翻訳を使った和文英訳処理の流れを見ていきましょう。
前処理
コンピューターが扱うことができるのは数値データのみです。前処理を行い、自然言語をコンピューターが処理できる数値データに変換する必要があります。
(1)文書を単語に分割する(形態素解析)
コンピューターに自然言語を処理させる場合は、単語単位で入力を行うのが一般的です。まずは文書を単語単位に分割します。この処理を形態素解析と呼びます。今回は形態素解析については詳細を記しません「単語を分割する仕組みがあるんだ、それをやってくれる仕組みがあるんだ」と理解いただければ大丈夫です。
今日はいい天気です → '今日' , 'は' , 'いい' , '天気' , 'です'
(2)数値表現に変換する
次に分割した単語をコンピューターが扱える数値に変換します。単語の数値変換によく使われるがone-hotベクトルです。語彙数分の次元を持つベクトルを準備し、単語に割り当てられた要素のみを1、他は0に設定することで単語を表現します。難しそうに聞こえますがやってることはシンプルです。
5つの単語、'今日' , 'は' , 'いい' , '天気' , 'です' をone-hotベクトルで表現してみましょう。
'今日' → 1 (1,0,0,0,0)
'は' → 2 (0,1,0,0,0)
'いい' → 3 (0,0,1,0,0)
'天気' → 4 (0,0,0,1,0)
'です' → 5 (0,0,0,0,1)
単語1つ1つに通し番号をつけるようなイメージです。ここでは簡単のため5つの単語で説明したので5次元ベクトルになりましたが、実際は日本語の語彙はもっともっとたくさんあるのでベクトルはもっと高次元になります。今回説明するシナリオでは日本語、英語とも20,000次元のone-hotベクトルを使う想定にしています。
*ベクトルというと難しそうですが、要するにこういうふうにいくつかの数字を並べてセットにしたものです。上の例では5つの数字がならんでるので5次元ベクトルといいます。
ニューラル翻訳の構成
ニューラル翻訳の処理は大きく前半と後半に分けることができます。
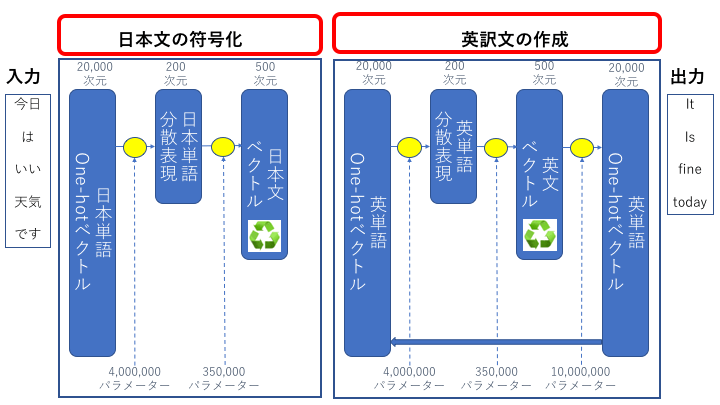
『前半:日本文の符号化』翻訳対象の日本文の情報を詰め込んだベクトルを作成します。
『後半:英訳文の作成』前半で作成したベクトルを使って英訳文を作成します。
前半 : 日本文の符号化
ここでは入力された日本語情報を詰め込んだベクトルが作成されます。このパートは2つの層で構成されています、それぞれの層を見ていきましょう。
(1)単語を符号化する(分散表現)
ニューラル翻訳の最初の層です。この層では入力されたone-hotベクトルを分散表現ベクトルに変換します。
one-hotベクトルは通し番号振ってるだけに等しいので、単語と単語の類似性とか関連性などを表現できません。そこでこの層で入力のone-hotベクトルを、複数のベクトル要素で単語を表現する分散表現ベクトルと呼ばれるものに変換します。学習を通じて分散表現が適切な値に設定されれば、意味の似た単語は似た分散ベクトルの値というように単語の関連性を表現できるようになります。
下記の例では5次元のone-hotベクトルを3次元の分散表現に変換しています
'今日'→ 1 (1,0,0,0,0) 分散表現 (0.3, 0,4, 0,5)
'は' → 2 (0,1,0,0,0) 分散表現 (0.2, 0,8, 0,3)
'いい'→ 3 (0,0,1,0,0) 分散表現 (2.0, 0.6, 3.0)
'天気'→ 4 (0,0,0,1,0) 分散表現 (0.6, 3.2, 5.0)
'です'→ 5 (0,0,0,0,1) 分散表現 (1.3, 4.5, 0.4)
one-hotベクトルは5次元のベクトルのうち1つだけ1で他は0でした。一方分散表現では3次元のベクトルの複数のベクトル要素に値がセットされ単語を表現しています。複数のベクトル要素で表現しているので分散表現と呼ばれます。
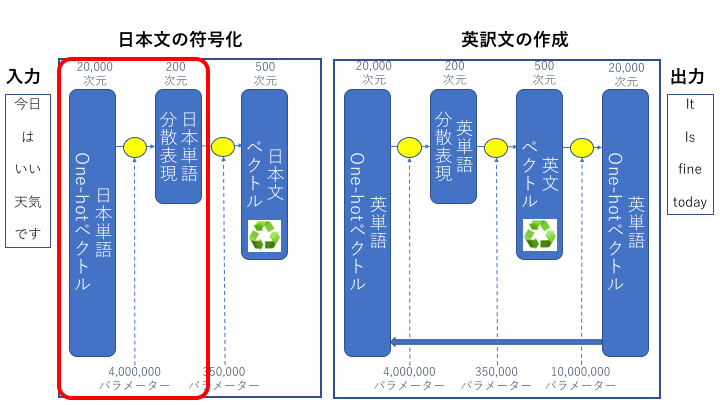
こちらの例では20,000次元のone-hotベクトルを200次元の分散表現に変換しています。
(2)日本文を符号化する
前の層で分散表現に変換された単語を順番に入力して、日本語の文書のベクトルを作成します。この層は作成されたベクトル情報を次のステップで入力として使う再帰ニューラルネットワークという仕組みになっています。
例を使ってみてみましょう。
Step#1 '今日' → 日本文ベクトル#1
Step#2 'は' + 日本文ベクトル#1 → 日本文ベクトル#2
Step#3 'いい' + 日本文ベクトル#2 → 日本文ベクトル#3
Step#4 '天気' + 日本文ベクトル#3 → 日本文ベクトル#4
Step#5 'です' + 日本文ベクトル#4 → 日本文ベクトル#5
料理に例えると、調理して作ったものに新しい素材を加えて、段階的に調理をしていくイメージです。
素材 '今日' を使って調理し、'日本文ベクトル#1'を作成。
'日本文ベクトル#1' に素材 'は' を加えて調理し、'日本文ベクトル#2' を作成
'日本文ベクトル#2' に素材 'いい' を加えて調理し、'日本文ベクトル#3' を作成
'日本文ベクトル#3' に素材 '天気' を加えて調理し、'日本文ベクトル#4' を作成
'日本文ベクトル#4' に素材 'です' を加えて調理し、'日本文ベクトル#5' を作成
常に前のステップで作ったものを再利用する構造になっているので、最終的に作成された日本文ベクトル#5には日本文を構成する全ての単語情報が入っています。
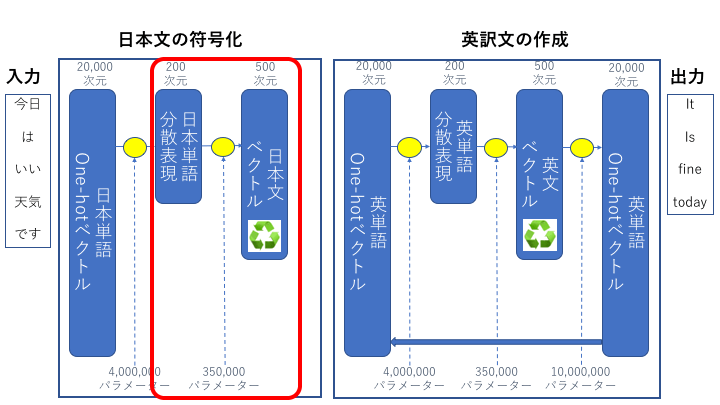
日本文ベクトルは文書の長さに関係なく固定長です、こちらの例では文書ベクトルは500次元です。
後半:英訳文の作成
ここでは前半に作成された日本文ベクトルを元に英訳文を出力します。
Step#1 日本文ベクトル#5 + BOS → 英文ベクトル#1 → "It"
Step#2 英文ベクトル#1 + "It" → 英文ベクトル#2 → "is"
Step#3 英文ベクトル#2 + "is" → 英文ベクトル#3 → "fine"
Step#4 英文ベクトル#3 + "fine" → 英文ベクトル#4 → "today"
Step#5 英文ベクトル#4 + "today" → 英文ベクトル#5 → "EOS"
一番最初(Step#1)と2回目以降で動きが異なります、それぞれの動きをみてみましょう。
一番最初(Step#1)の動き
前半パートで作成した "日本文ベクトル#5" とこれから英文開始しますという特殊文字記号 "BOS:(Beginning Of Sentence)" を入力に処理を行い、"英文ベクトル#1"が作成されます。
作成された"英文ベクトル#1"を入力に処理を行い、英訳文の最初の単語 "It" が作成されます。
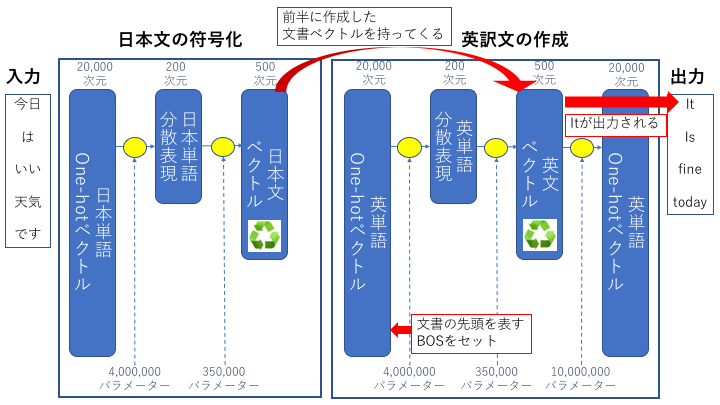
2回目以降の動き
2回目以降は前のステップで作成された英文ベクトルと英単語を入力に処理が行われます。
2回目の動きを具体的に見てみましょう
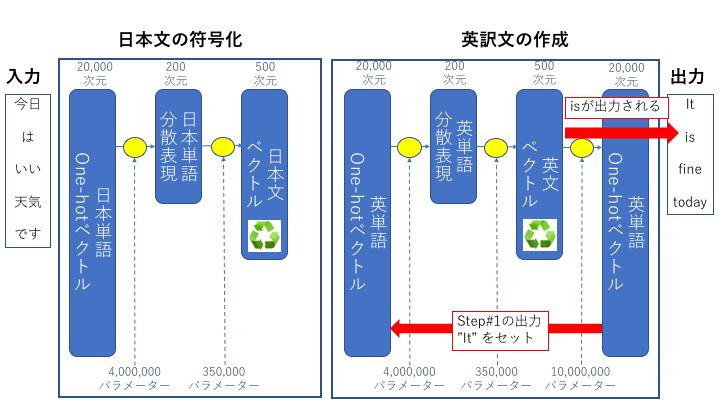
- Step#1で作成された"英文ベクトル#1"と英単語 "It"を入力に"英文ベクトル#2"が作成されます
- 作成された"英文ベクトル#2"を入力に変換処理を行い、英訳文の2番目の単語 "is" が作成されます
3回目以降も同じように処理を繰り返して行き、文章の終わりを示す特殊文字"EOS:(End of Sentence)"が出力されたら終了します。
注:今回はニューラル翻訳のもっともシンプルな形態を説明しています。実際に使われているものはさらに多層になっていたり、応用手法が使われていたりします。
使う前に学習が必要です
この仕組みを使う前には適切なデータを使って学習(ニューラル翻訳を構成するパラメーターを適切な値に設定)する必要があります。
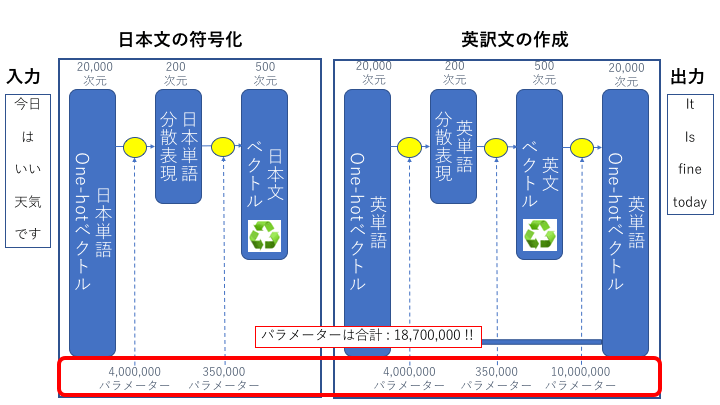
今回説明に使ったニューラル翻訳の場合、学習対象のパラメーターの数は18,700,000となります。今回の構成は説明のためシンプルな構成なので、実際に使われる構成のパラメーター数はもっと大きな数になります。
この膨大な数のパラメーターに対して適切な学習を行うためには適切な量の学習データと高いハードウェア性能が必要です。
ニューラル翻訳の可能性
ニューラル翻訳が注目を浴びているのは、従来の手法では実現できなかった高い翻訳精度を実現したためですが、この仕組みにはさらに大きな可能性があります。以下ニューラル翻訳の特徴と可能性について述べます。
シンプルである
ニューラル翻訳の場合学習に必要なのは対訳データのみです。実はこれは以前の機械翻訳の手法に比べると非常にシンプルです。
以前の手法では自然言語の処理を行う複数の部品を組み合わせて、機械翻訳の仕組みを作る構成になっていました。この手法だとまず各構成部品に特化した学習を行い、その後それらを組み合わせて作った機械翻訳の仕組みに対して学習を行うという手順を踏む必要がありました。また、各部品に特化した学習に必要なデータは人為的に作る必要がありました。
ニューラル翻訳では1つのニューラルネットで翻訳を行うので学習データとして必要なのは対訳データのみとシンプルです。また学習に必要な対訳データは人為的に作成しなくても大量なデータが存在する場合が多く、学習データが得やすいという特徴があります。
他分野での活用
今回紹介した和文英訳の処理では「入力が日本語、出力が英語」という構成でしたが、ニューラル翻訳で使われている仕組み(系列変換モデルと呼ばれています)を応用すると「入力が画像、出力はその画像の要約文」というように様々な入力、出力の組み合わせをカバーできる可能性があります。
最後に
今回説明したニューラル翻訳の他にも、今のAIブームを支えている技術には大きな可能性を持ったものが多くあります。これらの技術を正しく活用するためには、擬人化表現の背後にある、それぞれの技術の実装を正しく理解することが重要であると筆者は考えます。
****** Twitter 始めました *******
https://twitter.com/kenrohmiyoshi
参考書籍
深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ)
https://goo.gl/hP3dyc
ウェブデータの機械学習 (機械学習プロフェッショナルシリーズ)
https://goo.gl/nozyPj
岩波データサイエンス Vol.2
https://goo.gl/drKnBU