俺的間違いないラーメン店を統計的に選ぶ方法
みなさんはラーメン、好きですか?
著者は奥様が留守の日曜日の昼にラーメンを食べることを細やかな楽しみにしています。
友人からの口コミやら、NAVERまとめやら、口コミサイトを駆使して、自分好みのラーメン店と思しき店に足を運びます。
期待に胸を膨らませ、ついに心待ちにしていたラーメンが目の前に。
がしかし、一口スープをすすった時にふとした違和感。
そして、麺を頬張った時に感じる絶望感。
一週間分の期待を裏切られた時のあの気持ちといったら...
こんな気持ちは二度と味わいたくない。
味わうのは芳醇な香りに包まれたラーメンだけでいい。
というわけで、今回は統計的に間違えないラーメン店選びの方法を考えてみます。
分析対象データの作成
どうすれば、自分的間違いないラーメン店にたどり着けるのでしょう。
客観的・定量的にラーメンを評価する指標があり、自身の好みの店舗に近しい指標があれば、間違える確率は低い。著者はそう考えました。
そのアイデアを端的に少ない指標で表現しているのが××ログのような口コミサイトです。
がしかし、ラーメンには同じ点数で表現されていても実際は特徴が異なることが多く同一点数=同一の味にはなりません。
そこで、店のラーメンを複数レビューから客観的、定量的に表現することを考えました。
分析対象データとして使用するのは、某グルメサイトの人気ラーメン店都内トップ64店舗のレビューです。
1店舗あたり10レビュー、約48万文字を対象とします。
先ず、レビューからKHコーダーでラーメンの味の特徴を表現できそうな単語を抽出します。
"ヤサイ"、"野菜"などは別の単語と認識されてしまうので、アナログで名寄せしておきます。
結果、こんな単語150語を抽出しました。

あらいいですね~。
見ているだけで胸躍る単語が抽出されました。
単語だけでラーメン心くすぐられますね。
お店データを抽出単語を使って特徴づけ
次に、この単語群がレビューに出現する頻度をお店ごとにまとめます。
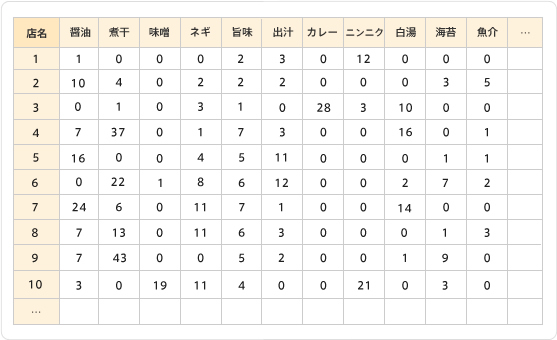
お店の特徴を単語の出現頻度で定量的に表していることになりますね。
単語ごとに出現頻度には大小がありそうなので、標準化することにします。
標準化とは、平均0、標準偏差1になるように数値を変換することです。
まぁ例えば"醤油"とか"豚"みたいな単語は頻度高く出現するのに対して"ソース"などの単語は出現する頻度が少ないので、このままだと同じ基準で測り難いですよね?
なので、評価基準が一様になるように変換するくらいの意味でとらえてください。
標準化すると先ほどの表はこんな感じになります。
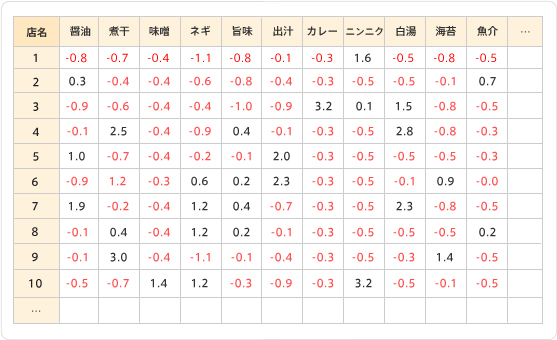
店舗4は"煮干"と"白湯"が多く出現し、店舗10は"ニンニク"が多く出現して、各々ラーメンを特徴づけているようですね。
それにしてもたまりません。今日のお昼はラーメンにします。
この状態でもなんとなくお店の特徴はわかりそうですが、150ある説明変数の組み合わせから類似店を探すのはなかなか骨が折れそうです。
お店の特徴から、お店間の類似度を計算する
お気に入り店の類似店を探すために、単語の出現頻度からお店間の相対的距離を計算します。
今回はお店ごとの類似店の分かれていく過程も見たいので、階層的クラスタリングという手法を使います。
階層的クラスタリングでは、最も距離の近い組み合わせを順番に見つけていくことでクラスタを構成していきます。
ということは、ラーメン店の分岐のしかた=特徴の分かれ方も併せて分かります。
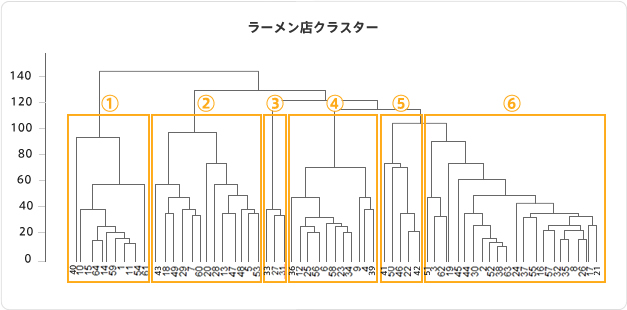
今回は大きく分かれた6個のところで各クラスタの特徴を見ていこうと思います。
クラスタ番号を左から1~6とします。
それではクラスタごとの特徴を見ていきましょう。
クラスタ間で特徴に大きく違いが出た因子だけをピックアップしてレーダーチャートで可視化しました。
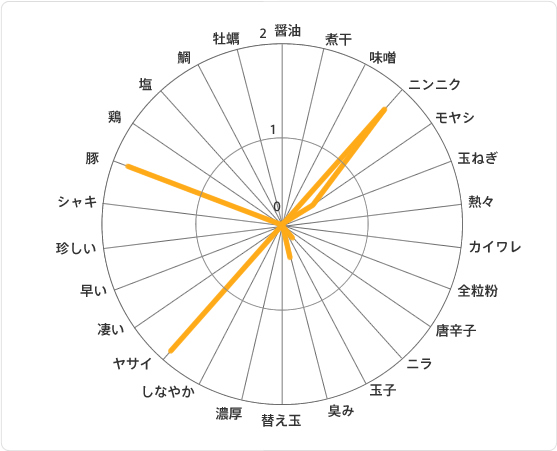
クラスター①は「ガッツリ漢マシマシ汗だく系クラスター」です。
「豚」「ニンニク」「ヤサイ」に特徴が出ています。
若い頃、毎日のように食べてたいわゆる二郎系と言われるアレですかね。
学生、サラリーマンが汗かきながらガッツリ食べてる様子が目に浮かびます。
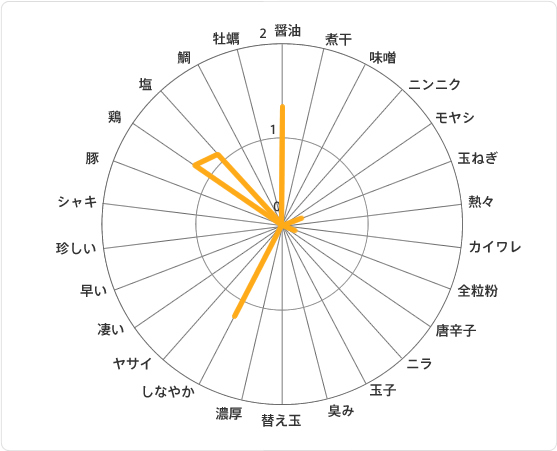
クラスター②は「都会派爽やかカップルでもいけちゃうね系クラスター」です。
「しなやか」「鶏」「塩」「醤油」とさわやかな単語が頻出しています。
普段オサレ店で食事しているカップルが"今日は趣向を変えてラーメン。でも脂とかニンニクはちょっと~"的に来店するイメージですかね。
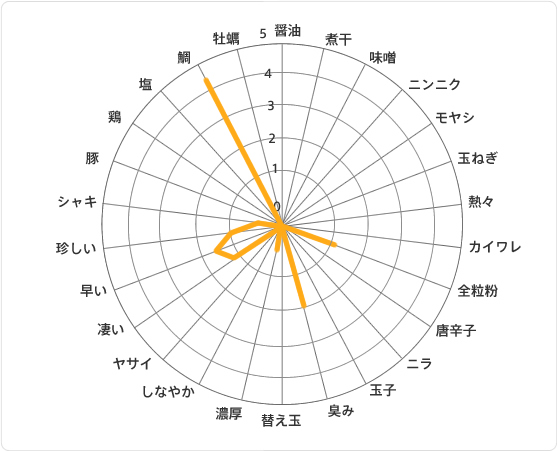
クラスター③は「贅沢大人ラーメンじゃなくてソバなら食べるよ系クラスター」です。
なんと、"鯛"という単語が出てきています。
該当店舗を調べてみると本当に鯛からスープをとってきているんですね。併せて「臭み」「早い」という単語が出てきてますが独特の臭みがあって、「早い」のは該当店舗のオペレーションがいいんでしょうね。
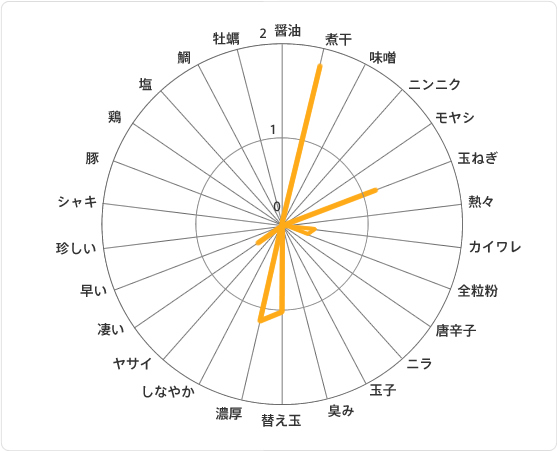
クラスター④は「煮干し玉ねぎ濃厚なんで替え玉もいけます系クラスター」です。
「煮干」「濃厚」「玉ねぎ」「替え玉」に特徴が出てます。
これは完全に著者好みのラーメンです。煮干と玉ねぎの濃厚さに思わず替え玉というストーリーがリアルすぎます。
煮干サイコーです。
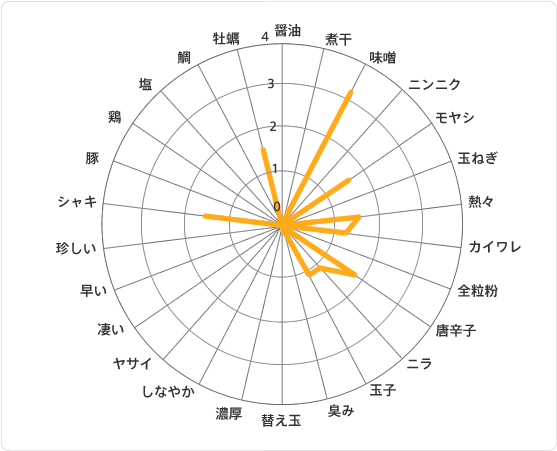
クラスター⑤は「味噌ラーメンはおかずです系クラスター」です。
「味噌」「モヤシ」「唐辛子」「ニラ」「玉子」「シャキシャキ」「牡蠣」など味噌と具関連の単語が多いという特徴があります。
味噌系で具だくさんのラーメン、イメージありますね。これもなかなかいいもんです。
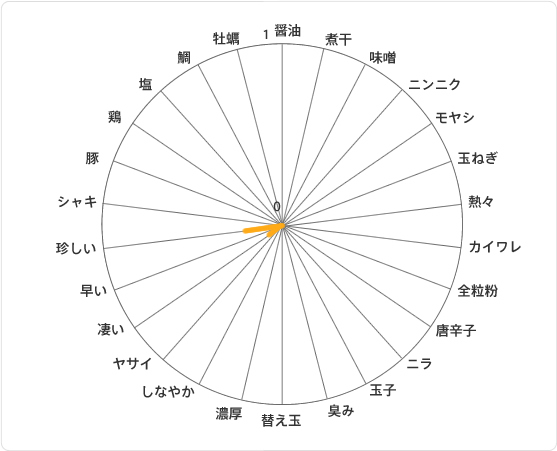
クラスター⑥は「ザ・マジョリティ系クラスター」です。
...。
なんというか殆ど大きな特徴が抽出できていないクラスターです。
それでも人気店なので、万人受けする優等生タイプのお店ということでしょうか。
今回の対象が各店舗10レビューなのでもう少し多くのレビューを各店舗集めれば特徴が抽出されると思います。
まとめ
今回は、レビュー内容から各お店のラーメンの特徴を指標化し、更に分類し自分好みのクラスタを見つけるということを試してみました。
サンプル数の少なさから微細な特徴が抽出できなかったのが若干心残りですが一応クラスタごとに特徴が出てうれしいです。
尚、著者が好きな店舗二つはいずれもクラスタ4に入っていたのでクラスタ4の他店舗にも足を運ぶことは確実になりました。
それ以外にもおすすめのラーメン店があったら教えてください。
それでは。