NanoPiでProDHCPを実行すると・・・
先日、ラズパイよりさらに小さなNanoPiを紹介しましたが、たまたま社内で、
「重たいOSやアプリはCPUを食うから困るよね〜。冷却ファンが必要になると、ゴルフ練習場の現場とかに設置すると毎回埃だらけになって壊れやすいし・・・。ProDHCPなんかARMのCPUでも動くくらい、軽くてコンパクトなのに!」
と話しをしていたのですが、そういえば最近ARMでProDHCPを動かしていないな、と思い、最新版をARMで動かしてみました。もちろん、まずはNanoPiから。
[NanoPi NEO2]
NanoPi NEO2はラズパイをはるかに超えるCPUパワーと、ネットワークチップを搭載して1Gbpsリンクする、見かけによらずパワフルなボードです。uname -aで見ると分かるように、64bitです!
Linux NanoPi-NEO2 4.11.0-rc4 #37 SMP Thu May 4 01:43:10 CST 2017 aarch64 aarch64 aarch64 GNU/Linux

245IPの1セグメントで起動し、dhcpperfで負荷テスト。dhcpperfは私の勤務先で無償提供しているDHCP負荷テストツールです。
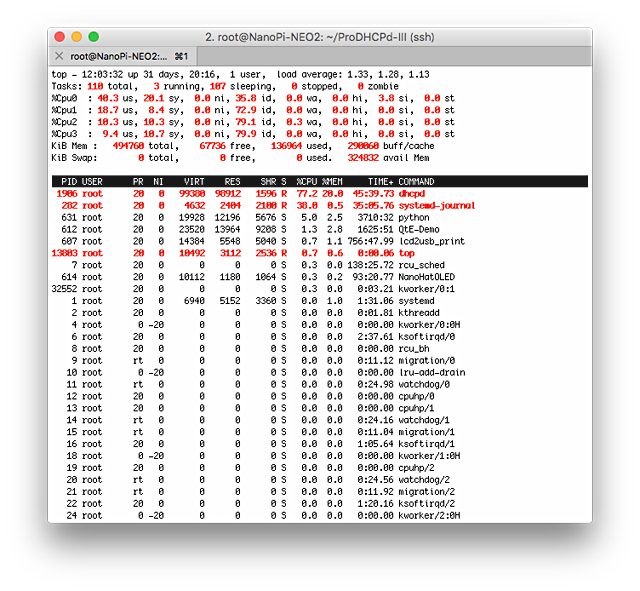
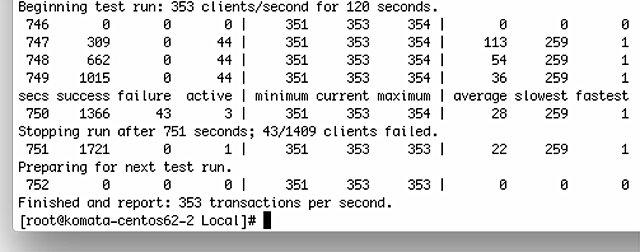
dhcpperfはDISCOVER→OFFER→REQUEST→ACK→RELEASEを1トランザクションとして測定しますが、秒間353払い出しという結果です。これは予想外の素晴らしい数値ですねぇ。後ほどインテル系CPUでの様子も紹介しますが、まさかARMでここまで出るとは思っていませんでした。
ちなみに、今回は全てのテストを、私を含めたIT関連メンバーが使っている社内セグメントをそのまま使い、ポート番号だけ67,68番ポート以外にして強引に実験していますので、あまりテスト環境としては良い状態ではありません。もちろん、社内メンバー達からすれば余計なトラフィックを流されて迷惑だったでしょうけれど。まあ、DHCPパケットくらいなら大したことはありませんね。
気をよくして、100万IPの設定で実験。そこそこの回線事業者規模ですね。
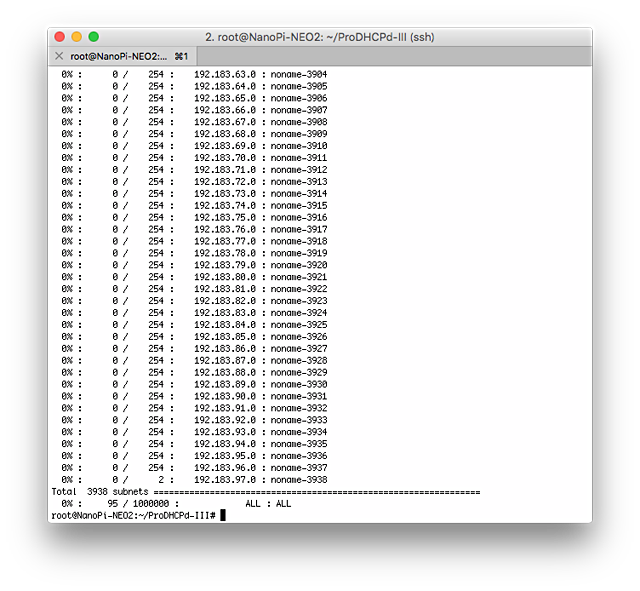
こんな感じで、/24のセグメントを3938個くらいで合計100万IPです。
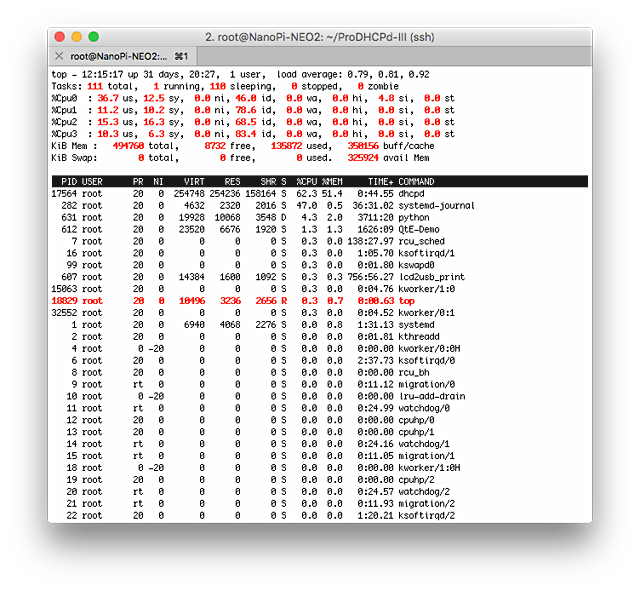
メモリー消費が増えましたが、何とかオンメモリーで動いているようです。
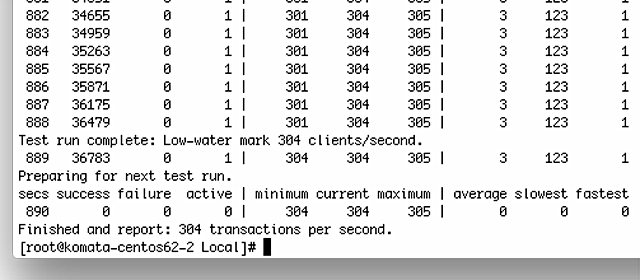
これでも秒間304払い出し。ProDHCPはセグメント数が増えても基本的には払い出し性能はほとんど変わりませんので、想定通りの動きです。
では、これで100万IPの運用でもNanoPi NEO2が使えるかというとそうでもなくて・・・
1000000 SigHupFunc:(1):Wed Dec 20 13:00:30 2017
main:dhcpd ready ::: Wed Dec 20 13:01:18 2017
48秒
設定反映に48秒もかかってしまいます。ProDHCPではSIGHUPを与えることで設定反映(というよりほぼプロセスの再起動)をしますが、48秒はちょっとかかりすぎですね。NanoPiはマイクロSDカードをRWマウントして動いていますのでI/Oが足を引っ張っている感じでしょう。インテル系サーバ機ではどのくらいかは後ほど紹介します。
さて、100万IPでも何とかなるので、300万IPでやってみました。300万IPは、回線事業者でも1サーバで運用するかどうか悩むくらいの規模です。ProDHCPとしては1000万IPでも1サーバで普通に使えるレベルですが、ネットワーク構成や運用も含めて、複数に分割するかどうかという規模です。
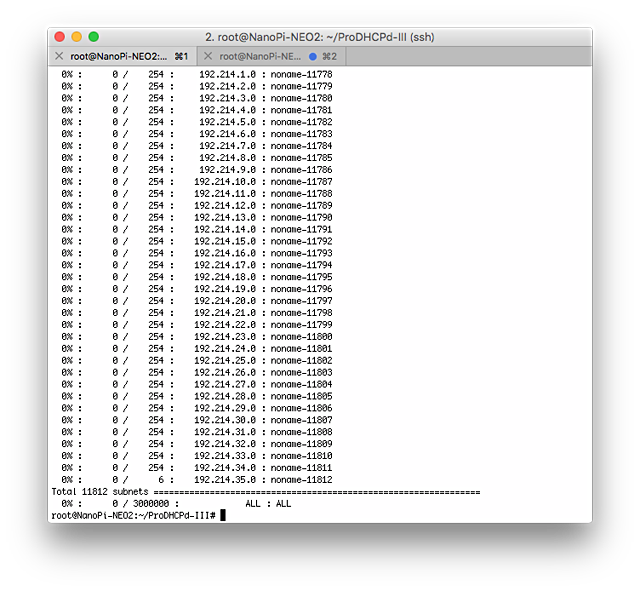
/24のセグメントを11812個くらいで300万IPです。
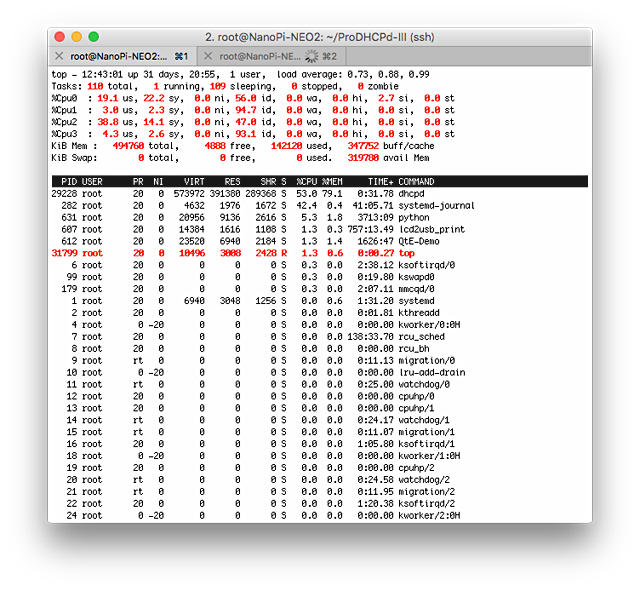
さらにメモリーサイズが大きくなり、VIRTとRESが一致しなくなりましたので、ページングしながら動いている感じです。
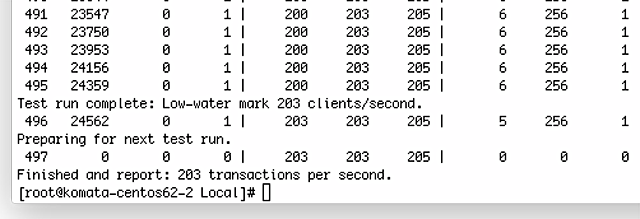
まあ、それでも秒間203払い出しくらい。
ただし、設定反映は・・・
SigHupFunc:(1):Wed Dec 20 12:55:03 2017
main:dhcpd ready ::: Wed Dec 20 12:58:37 2017
3分34秒
3分半もかかっては、設定変更が頻繁にある運用現場では使えませんね。とはいえ、動くことは動きますね〜。
[NanoPi NEO]
続いて、NanoPi NEOです。NEO2に比べると、CPUがスペックダウンし、ネットワーク用チップも搭載されず、100Mbpsリンクです。uname -aでみると、NEO2と違い32bitですね。
Linux NanoPi-NEO 4.11.2 #5 SMP Tue Oct 17 17:32:44 JST 2017 armv7l armv7l armv7l GNU/Linux

まず、245IPの1セグメントでやってみましょう。
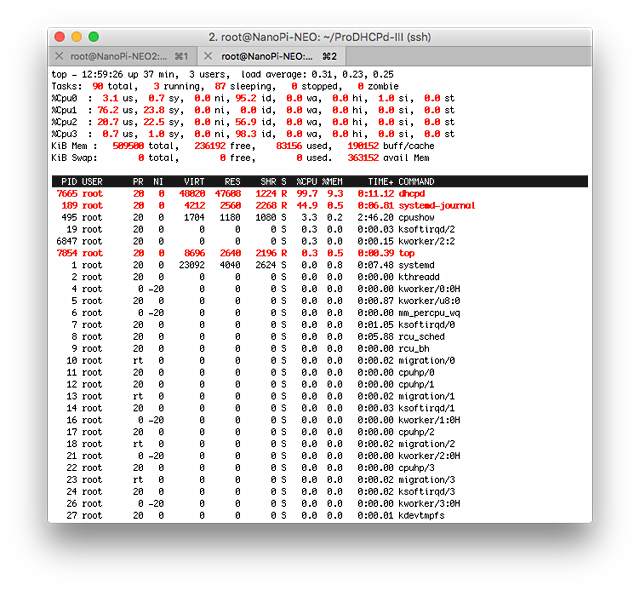
32bitなので、64bitのNEO2の半分くらいのメモリー消費で動いています。
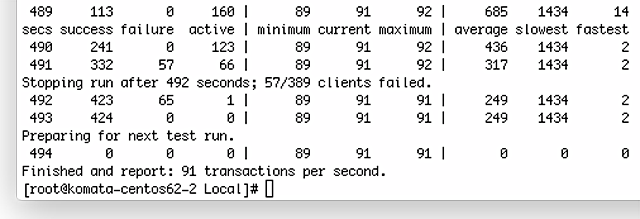
うーん、NEO2と比べると全く性能が出ませんね。100Mbpsリンクですので、dhcpperf側が1Gbpsリンクなので、受信し切れていない可能性が高いですね。
ということで、あまり気分が盛り上がらないので、100万IPや300万IPは諦め、次へ。。
[ラズパイ3]
ラズパイでは現時点での最新機種である「3」です。とはいえ、uname -aで以下のように32bitですし、ほぼNEOと同じくらいのものでしょう。ネットワークも100Mbpsリンクです。
Linux komata-pi1 4.9.52-v7+ #1038 SMP Fri Sep 29 16:26:52 BST 2017 armv7l GNU/Linux
こちらも245IPの1セグメントで実験してみます。
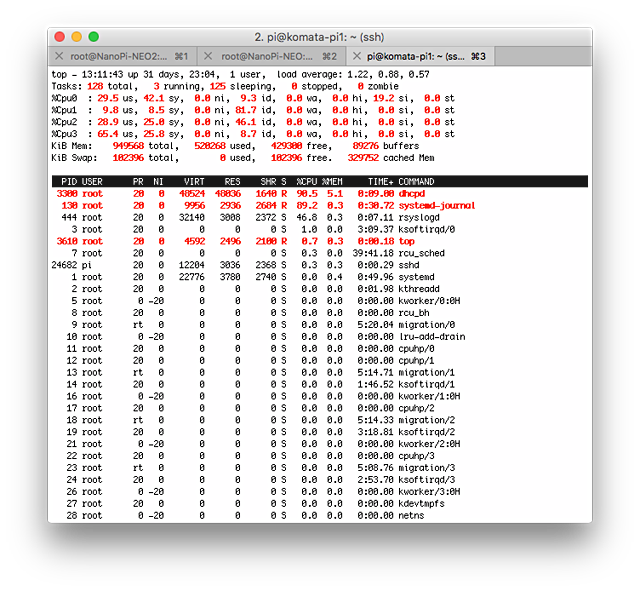
メモリー消費はNEOと同様です。
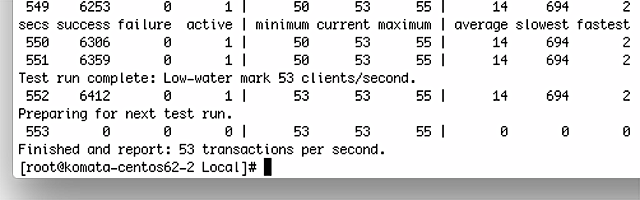
NEOよりさらに悪い数値でした。こちらもパケロスがそもそもの原因の可能性があります。
[インテル系サーバ機]
さて、ではインテル系サーバ機ではどうなのか?を見てみましょう。本当はもう少しまともな環境を用意したいところですが、公式なテストではないので、普段使っている適当なVM環境で、ネットワークも上記と合わせて社内セグメントをそのまま使いました。uname -aでわかるように、CentOS6.2の64bitです。
Linux komata-centos62-1 2.6.32-220.el6.x86_64 #1 SMP Tue Dec 6 19:48:22 GMT 2011 x86_64 x86_64 x86_64 GNU/Linux
さすがにサーバ機なので、最初から300万IPで見てみましょう。
NEO2と同じ64bitで動いていますので、300万IPのNEO2と同じくらいのメモリー消費です。
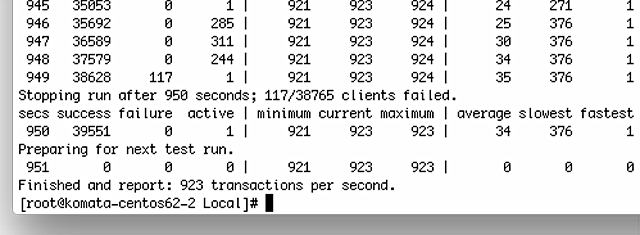
秒間923払い出しという結果です。実は、負荷テストでは300万IPあっても1セグメントに集中して測定しているため、/24ではなかなかこれ以上の性能を出すのが標準パラメータでは難しく、負荷のかけ方を工夫するとProDHCPでは秒間3000払い出しくらいというのが公式性能なのですが、今回は簡易的なテストですので・・・。
それよりも、300万IPで問題の設定反映時間ですが、
SigHupFunc:(1):Wed Dec 20 14:09:32 2017
main:dhcpd ready ::: Wed Dec 20 14:09:50 2017
18秒
300万IPでも18秒と、やはりサーバ機のディスクI/Oは速いですね。
ということで、NanoPi NEO・ラズパイはともかく、NanoPi NEO2は使い方によっては回線事業者レベルの規模でも使えるくらいでは?という感じでした。NanoPi NEO2が凄いのか、ProDHCPのプログラミングが凄いのかの判断は・・・自分で判断しないでおきます。まあ、実際に運用すると、マイクロSDのRWマウントはいくらなんでも回線事業者レベルではすぐに壊れそうな気もしますが・・・。

電卓より面積が小さいコンピューターも、実はかなり高性能です!